Pinecone
Overview
Pinecone is a cloud native vector database for building generative AI applications. See https://pinecone.io for more information. Qarbine supports native Pinecone vector query interactions. For example, the specification below
{
index : "sample-movies",
query: {
topK: 2,
vector: [ … ]
}
}
can return the answer set below. The structure on the first element is shown to the right.
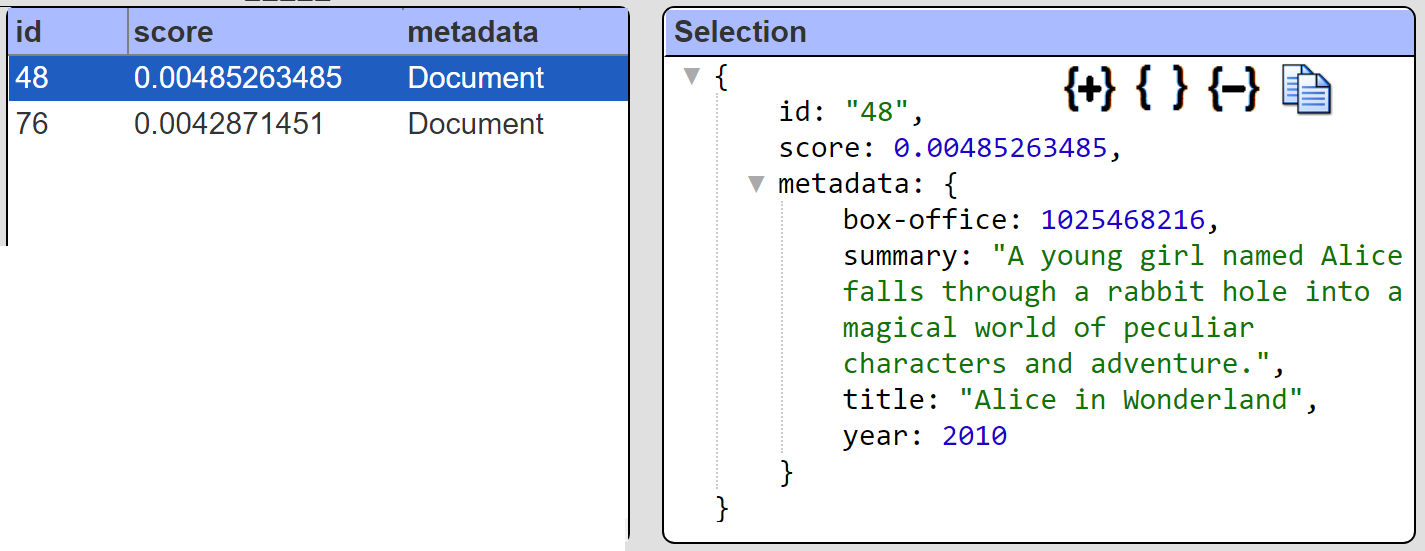
The vector argument above can be an explicit array of numbers or be dynamically determined using Qarbine’s integration with popular LLM services. Note that besides the standard Pinecone query interaction shown above, Qarbine also provides a convenient SQL oriented interface to retrieve Pinecone data. This interaction is described in more detail below.
The answer set row’s metadata can be an arbitrary JSON structure.
Qarbine can perform a Pinecone vector query and then easily analyze the data and format an analysis report. This interaction can also be embedded into applications for a seamless end user experience. This avoids painfully navigating application silos and losing context along the way. Sample output for this simple data is shown below.

There is no flattening of data such as is required by legacy SQL oriented tools with nested data structures. Pinecone has no native SQL interface anyway so even that burdensome approach is not available. Unlike legacy tools, with Qarbine the metadata can be a deeply nested data structure and it is left as-is.
Prerequisites
Prior to using Qarbine’s embeddings(...) macro function or the SQL-like query function nearText(...), the Qarbine Administrator must first configure an “AI Assistant. The AI Assistants provide access to various popular Generative AI services and are referenced using an alias. Check with your Qarbine administrator for which ones are available and their proper use. When using dynamic query vector embeddings, the model used by the AI Assistant must be compatible with the one used to generate the original embedding values in the database.
Defining a Data Source
Overview
A Data Source is a Qarbine component responsible for retrieving data from somewhere. At a high level it has a name, a description and some arbitrary query string which when sent to the associated Qarbine Data Service endpoint returns some data. The overall execution flow for an analysis, including the optional prompt component, is shown below.

A single data source can be referenced by name from multiple Qarbine template components. This enables a single point of change when perhaps, an index is added, or some other query tweak is necessary. The alternative is to attempt to find all templates impacted by a schema or index change for example. This component reusability is especially beneficial when team members have varying roles and skills.
Example
The specification below retrieves the first 2 similar movies based on the vector values.
{
index : "sample-movies",
query: {
topK: 2,
vector: [ … ]
}
}
Sample results are shown below.
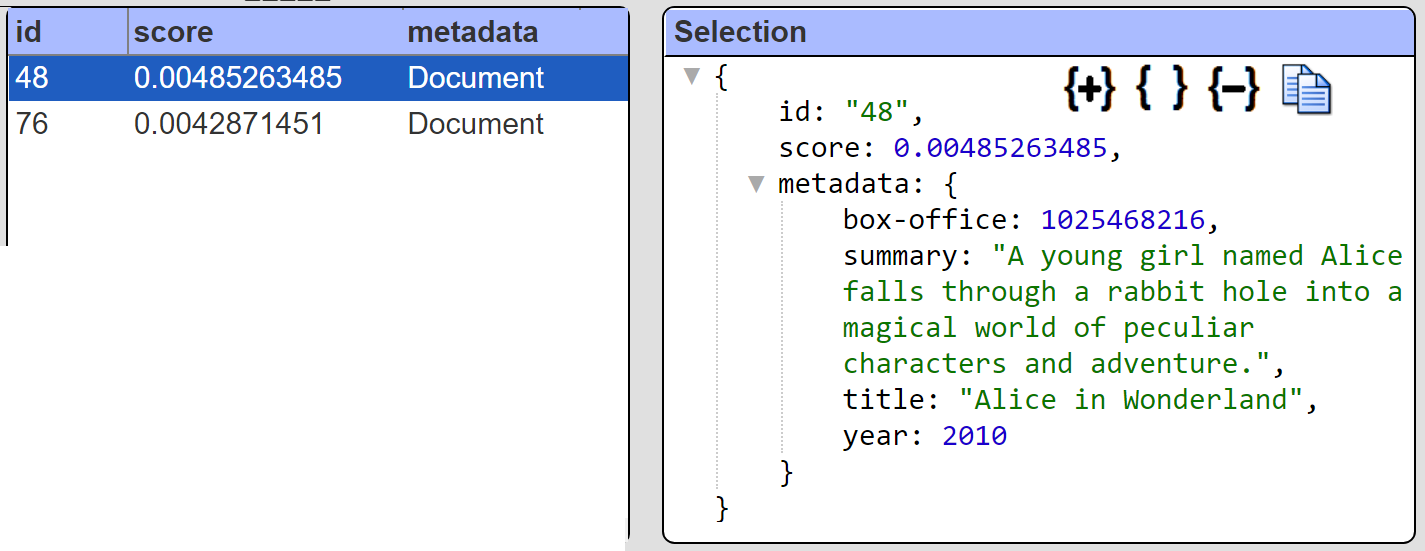
The primary data of interest is within the metadata field. Qarbine supports answer set manipulation via pragmas. We can adjust the Qarbine data source definition as shown below.

This results in the following much simpler answer set.
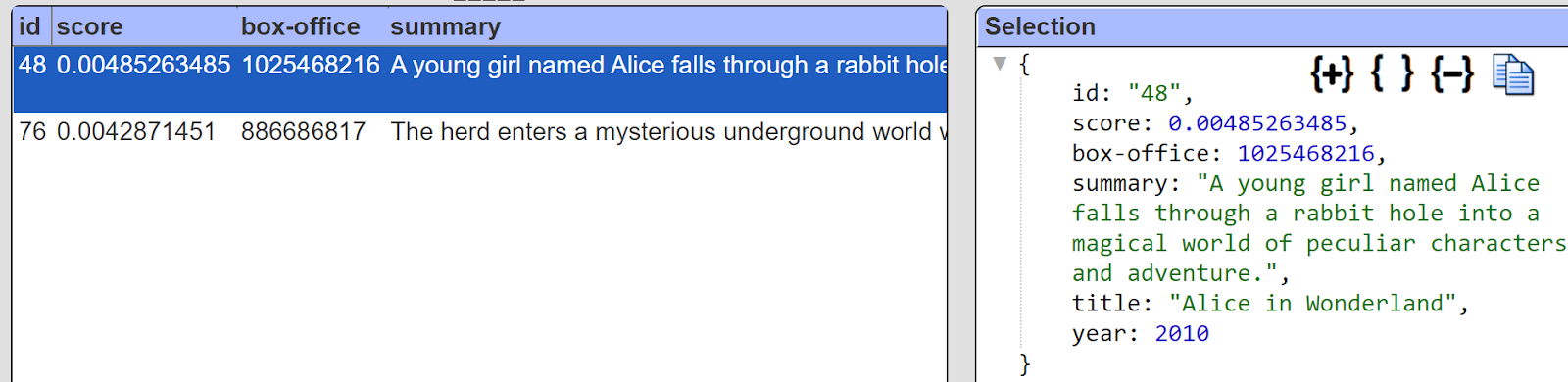
In analysis templates cell formulas to access the summary value can instead of using #metadata.summary, can use #summary. This also reduces the size of the returned answer set. Other pragma manipulations are possible as well. See the Data Source Designer documentation for more details.
The vector value in the Data Source’s definition can be a bit bulky to manage and is also likely not going to be hard coded as well. In an embedded scenario, your application can supply the vector and make use of a variable placeholder in the query definition. A sample definition using this approach is shown below.
{
index : "sample-movies",
query: {
topK: 2,
vector: @vector
}
}
Qarbine can be configured to access various generative AI services including those from Open AI, Microsoft Azure Open AI, and AWS Bedrock. Rather than directly setting the vector containing many numbers in the retrieval definition, you can have Qarbine obtain the vector value. This assumes the 1,536 dimensional model text-embedding-ada-002 matches your indexes data vector producer! Below is an example Data Source definition using this approach,
#pragma pullFieldsUp metadata
{
index : "sample-movies",
nearText: "dracula",
query: {
topK: 2
}
}
Rather than having the hardcoded above of ‘nearText: "dracula" ’ we can use a variable in the definition as well. Placeholders in the definition can be identified using “@variableName” or “[! macroExpression !]” syntax. For example,
{
index : "sample-movies",
nearText: @userInput,
query: {
topK: 10
}
}
Running this will first present a prompt for the userInput variable.
Enter the text to locate similar movies for.
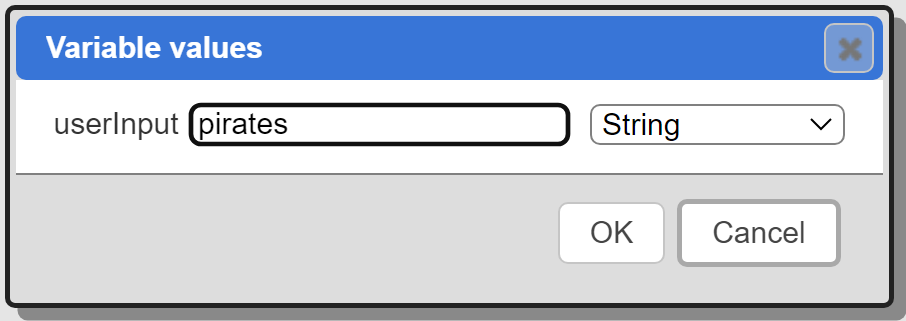
Click OK.
The query definition’s nearText field is set to “pirates” and the updated definition sent to the Qarbine backend. Qarbine retrieves the vector for “pirates” and sets that into the Pinecone query’s vector field argument. That query is sent to Pinecone and the results sent back to the Qarbine backend. The ‘#pragma pullFieldsUp metadata’ post processing then occurs. The final data is sent back to the Qarbine front end and shown. Below is an example result.

This style of end to end integration makes leveraging Pinecone’s generative AI and data features extremely easy for everyone- not just developers! Developer applications can rapidly gain Pinecone benefits and roll the capabilities out to end users.
Managing Answer Set Size
The default maximum number of rows starts off at 25 for a new data source. This is useful to evolve a query from a concept to one that you have verified returns the desired answer set. As noted, any native way of limiting an answer set size is the preferred approach. This setting is in the component dialog as shown below and also accessible by clicking the ‘Gear’ icon.
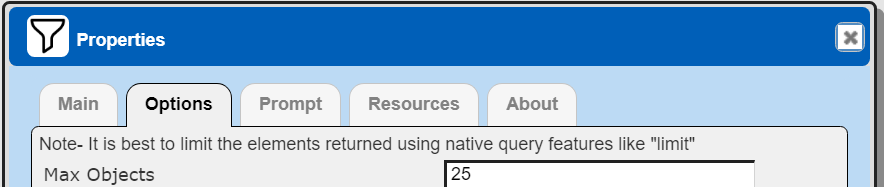
Once you are done drafting you can adjust this parameter. A “0” indicates there is no maximum. A number greater than 0 indicates to limit the final answer set size to that number of rows. This answer set truncation comes after any native query limit. So, if the answer set from the data endpoint is quite large, that content has to be returned to the Qarbine host. It then may truncate the number of rows. It is best to truncate at the query level (i.e., use a limit) to reduce the content sent from the data endpoint to the Qarbine host in the first place.
Adjusting the Maximum Rows
Recall the default maximum rows at the component level is 25. When you are satisfied with your query you can change that setting by clicking.

Adjust the setting to “0” indicating no Qarbine answer set truncation.

Click

Prompt Integration
Overview
Qarbine prompts provide a way to obtain runtime values and variables for data source and template execution. To avoid hardcoding, prompts can use macro formulas to run queries which populate list widgets. Prompts are defined in a no code manner using the Prompt Designer. Shown below is the execution flow when there is a Prompt component.

The Prompt Designer supports a large variety of input widgets including entry fields, check boxes, radio button groups, sliders, and file input.
Example
Let’s define a Qarbine Prompt component to obtain the userInput variable value to use in the Data Source. This will soon be leveraged from a Qarbine Template. The Prompt Designer is basically a no-code dialog builder. In this example we are only asking the user for a single value. Qarbine prompts can ask for many values and present entry fields, lists, checkboxes, radio buttons and other widgets.
The running prompt is shown below.
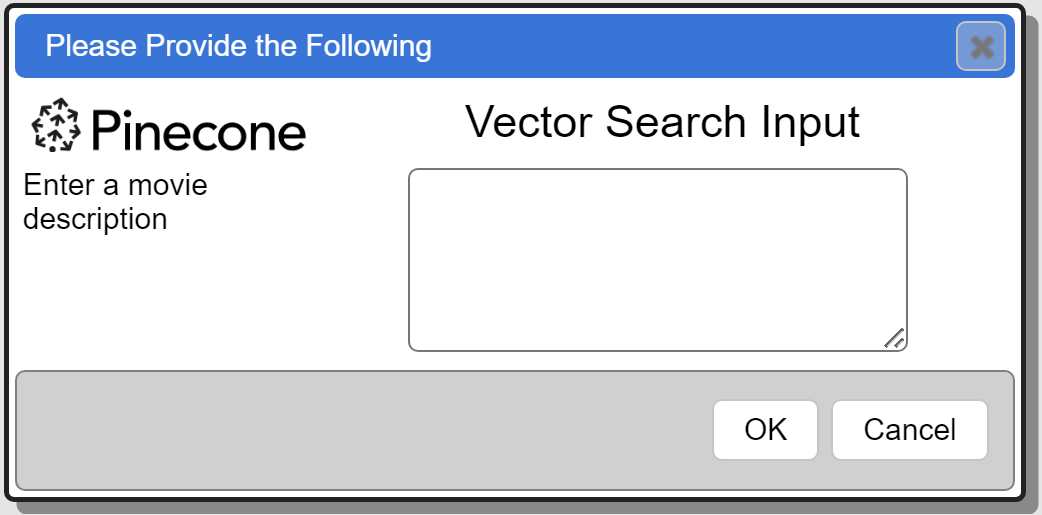
The Qarbine prompt component has 2 elements.

The first element is defined as
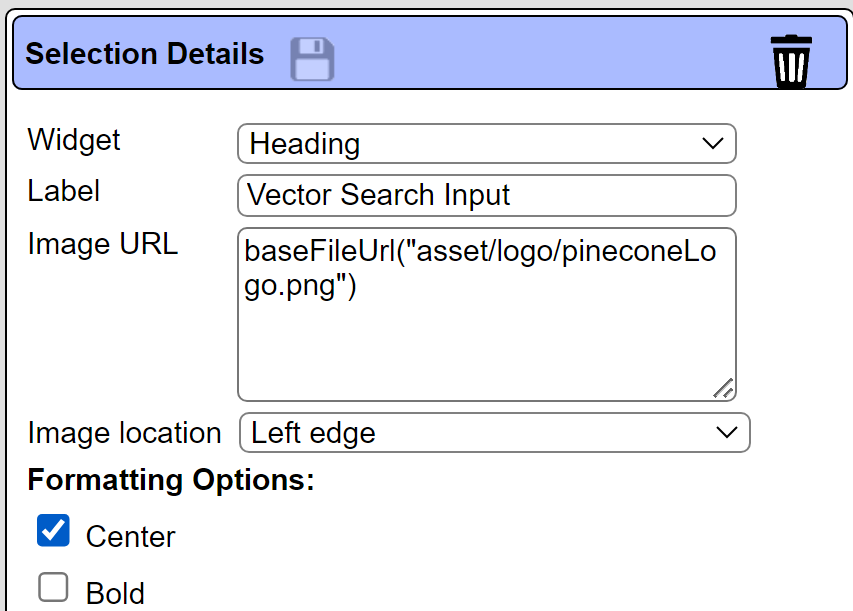
Notice the image URL can be a macro language expression and not just a simple string. The second element is defined as
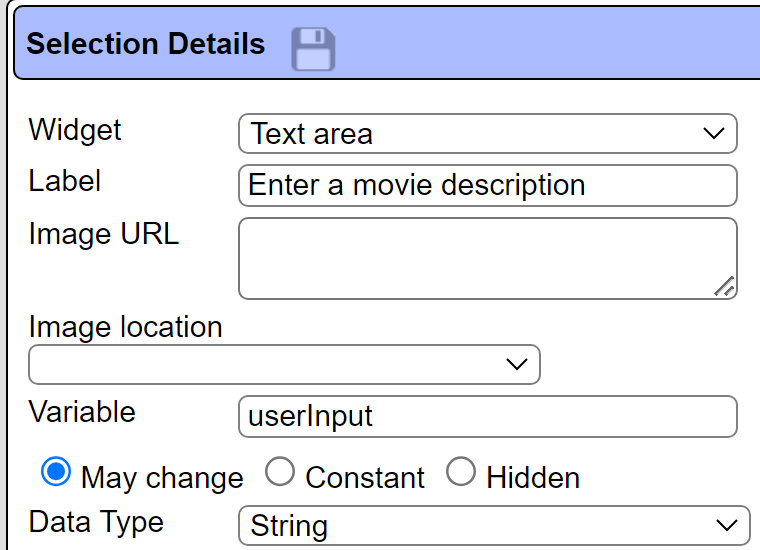
The component is saved in the Qarbine catalog and can be referenced by data sources and analysis templates.
Defining an Analysis Template
Overview
A template defines how to process the data being retrieved from Data Source queries and other data expressions. It also defines formulas, formatting options, and other analysis and presentation options. The overall execution flow for an analysis, including the optional prompt component, is shown below

Using the Template Designer
The result of running the about to be described template is shown below.

It presents movies from the sample movies index.
The template’s primary properties are shown below.
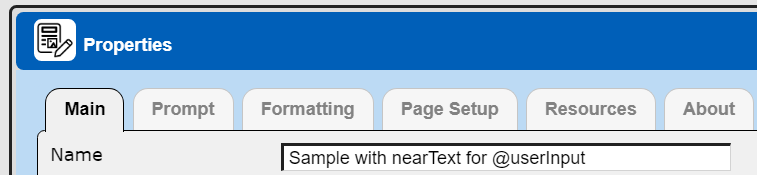
. . .

It uses the Data Source defined previously. It references the Prompt as shown below.
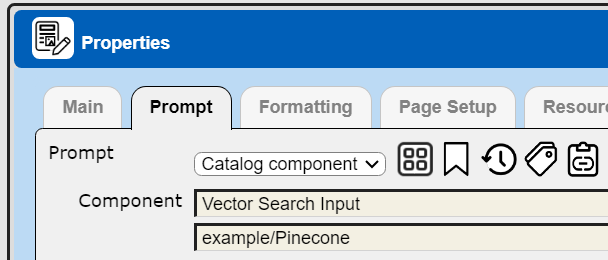
The general cell layout is shown below.
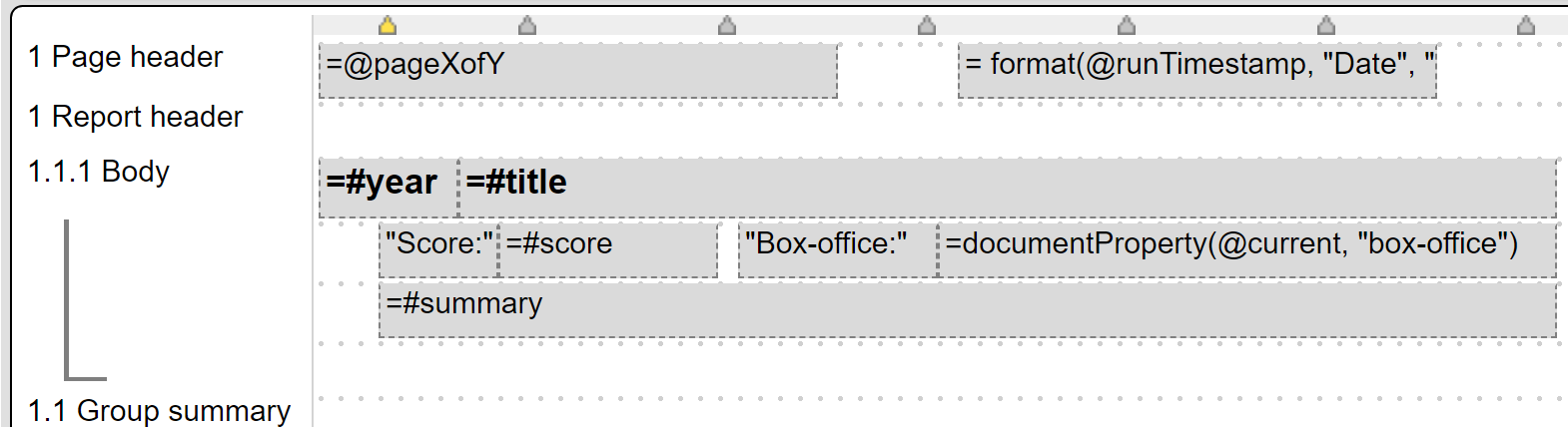
The right hand side of the Template Designer will show any metadata about the data source data. (There must be no cell chosen in the grid area for this to appear).
The first body line uses a 14 point, bold Arial font as a heading for all of its cells. The score, box-office, and summary values are shown below the heading. The documentProperty() function is used rather than the shortcut “#field” syntax because of the dash in the field name. The “@current” references the current data row being processed.
Running this first presents the dialog into which the user types into the text area.
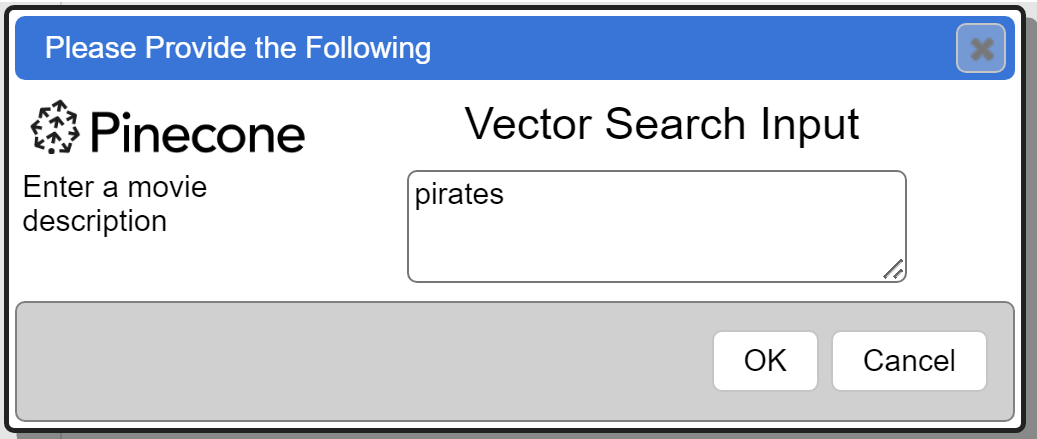
Clicking OK propagates that variable value into the template execution flow. As described above, the “pirates” userInput value flows to the Qarbine backend. Qarbine retrieves the vector for “pirates” and sets that into the Pinecone query’s vector field argument. The Pinecone query is sent to Pinecone and the results sent back to the Qarbine backend. This data is then processed based on the template definition. The result is then shown.
An Example of Pinecone Metadata Filtering
Pinecone supports filtering of rows based on their metadata. Consider the Pinecone query below which accepts user input for movie similarity plus a movie release year range
{
index : "sample-movies",
useEmbedding: @userInput,
query: {
topK: 10,
filter: {"$and": [{"year": {$gte: @startYear} }, {"year": {$lte: @endYear} } ] }
}
}
Running this within the Data Source Designer presents the general dialog below.
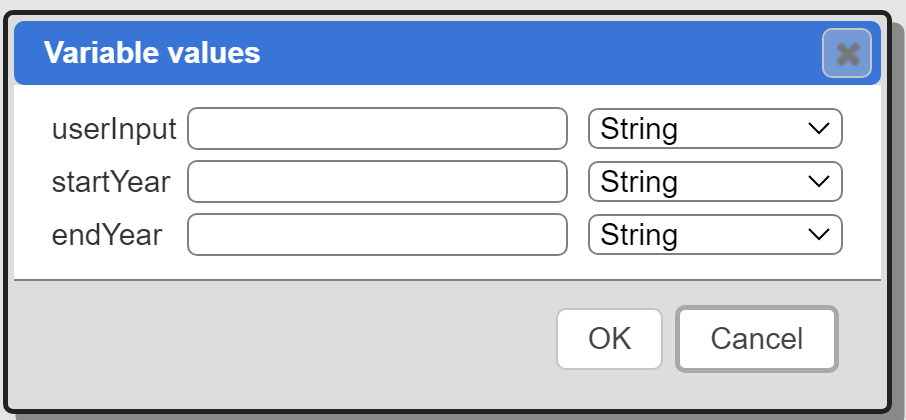
You can enter the values and adjust the data types as shown below.
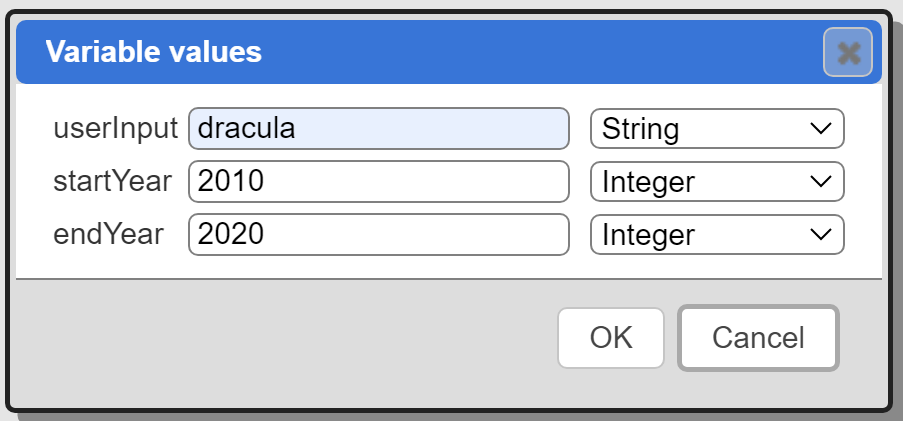
Click OK.
A portion of the result is shown below.

A Qarbine Prompt can be defined similar to the one described above to obtain the year range values. The presentation of that prompt is shown below.
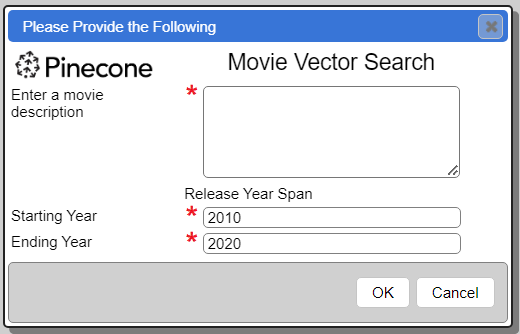
This is a much nicer user experience. Note that variables can also be programmatically provided when Qarbine is used in an embedded manner.
The elements of the prompt are shown below.
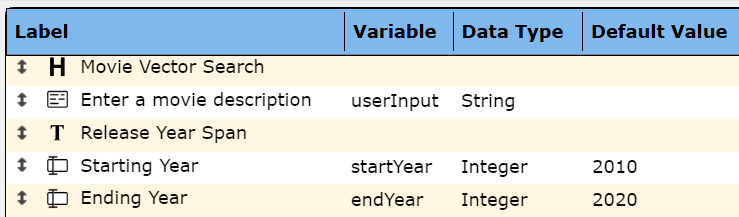
The first two are similar to the first prompt component described above.
The 3rd element is defined as
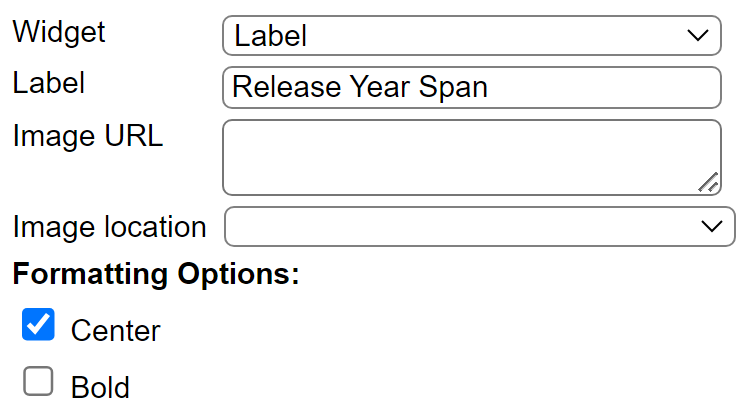
The 4th element is defined as

. . .
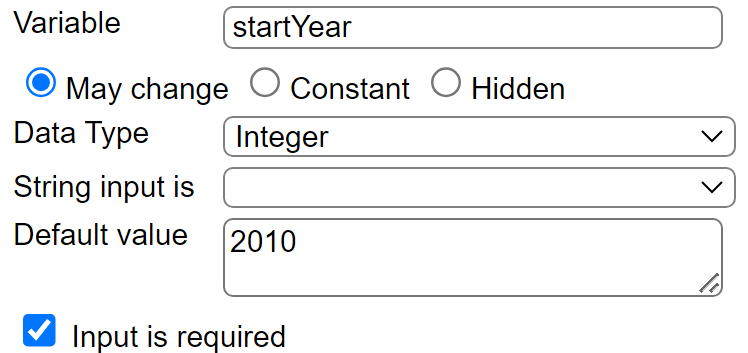
The 5th element is defined as

. . .
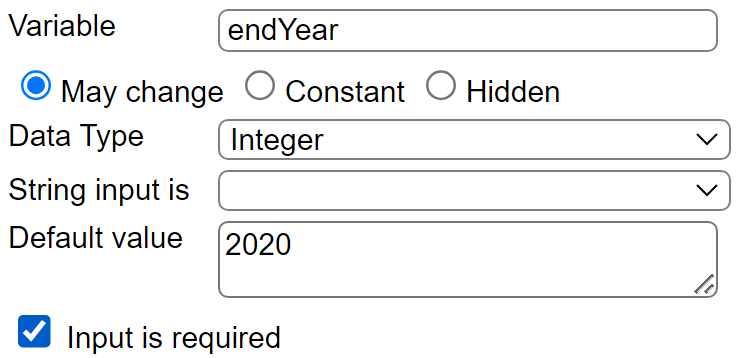
A new Template can be defined based on the first template which then references the new Data Source and Prompt components. Its properties are shown below.
. . .

The prompt reference is shown below.
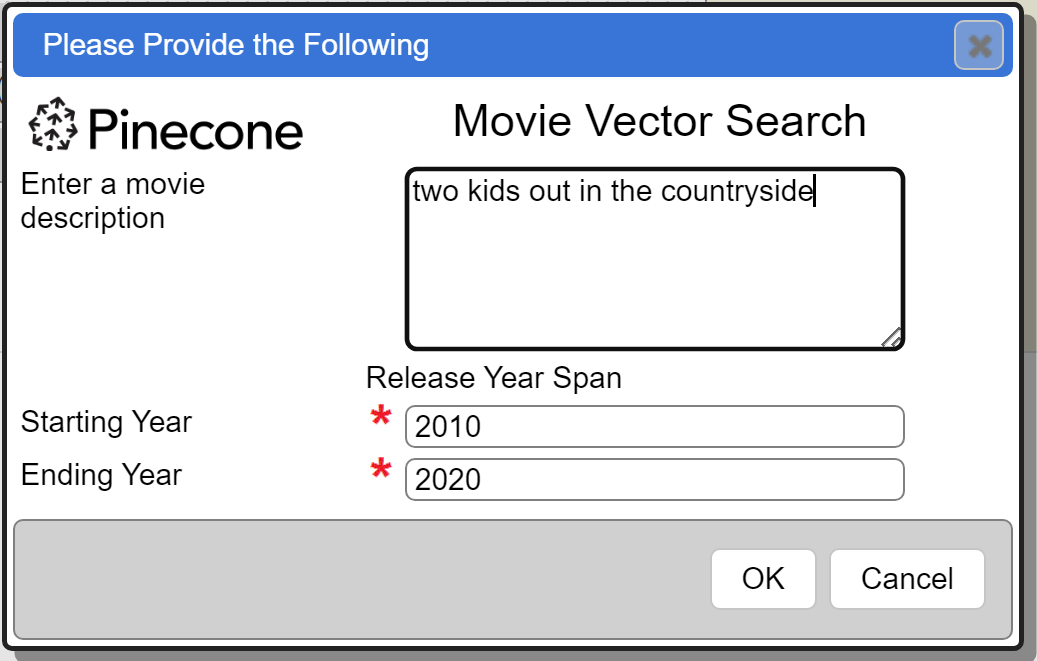
Running this presents the prompt dialog.
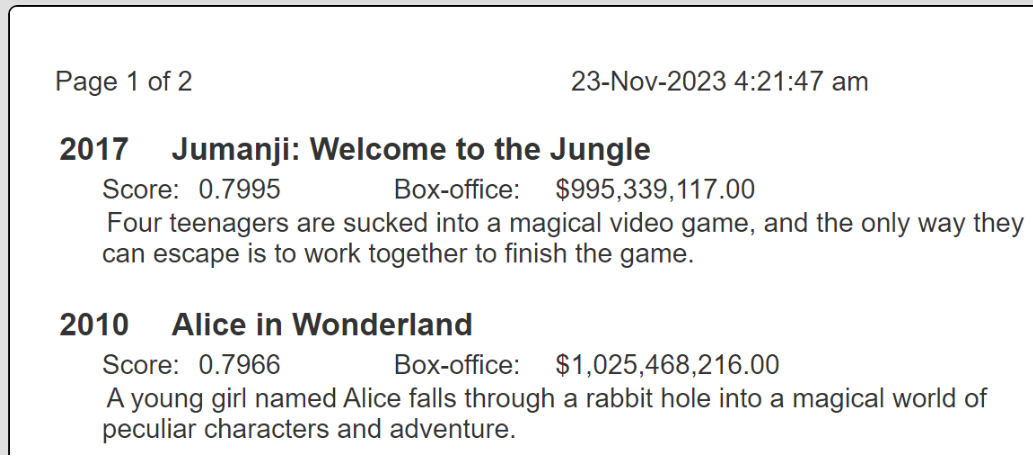
The prompt values flow into the variables within the Data Source query sent to Qarbine backend and eventually into a final query sent to Pinecone. The Pinecone answer set is then processed into an analysis result as shown below.
Query by Example and Report by Example
The Query by Example and Report by Example tools are aware of standard comparison operators. You may also use ‘BETWEEN x AND y’ criteria. An example is shown below.

Use the Data Source Designer for direct use of Pinecone filtering features.
Either _nearText or _nearVector criteria is required. Below are the entry styles for _nearText.
| Option | Description |
|---|---|
| phrase | The phrase is sent to the default Qarbine AI Assistant service to obtain the vector which is subsequently used by the database. |
| +alias phrase | The phrase is sent to the Qarbine AI Assistant specified by the alias to obtain the vector embedding list which is subsequently used in the database query. |
Below is an example of using the second syntax style.

The table below lists the entry styles for _nearVector.
| Option | Description |
|---|---|
| list of numbers in brackets | The embedding size must match the database’s expectations. |
To obtain the EXPLAIN information in Data Source Designer, QBE or RBE hold down the ALT key when clicking the run button.
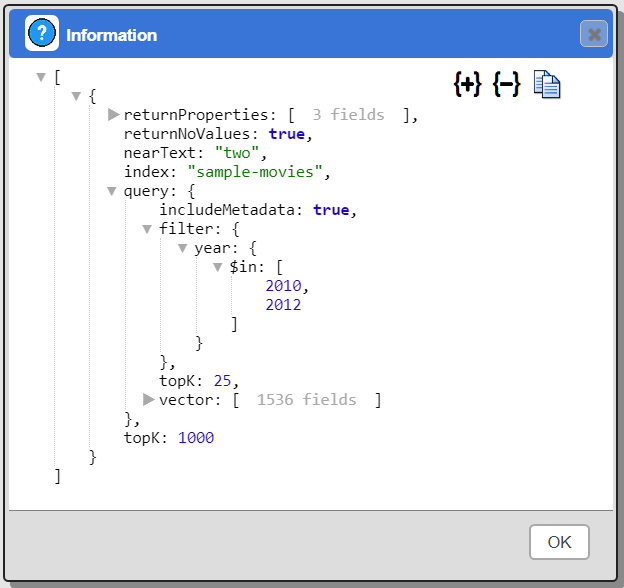
Troubleshooting
- The size of the query’s vector must match that of the index data being searched. Some Pinecone limitations are found at https://docs.pinecone.io/docs/limits
- Indexes in the gcp-starter environment do not support namespaces. see https://docs.pinecone.io/docs/starter-environment
- The default namespace is an empty string. For more information see https://docs.pinecone.io/docs/namespaces
Next Steps
Querying Your Database
For database specific interaction guides navigate to
References
See https://docs.pinecone.io for more information.