MongoDB API Star Wars Examples
Overview
This document covers the use of various Qarbine tools interacting with a Star Wars dataset that is stored in the Qarbine sample MongoDB database.
Report by Example
Overview
The Report by Example and Query by Example tools enable point and click and then fill in the blank interaction to rapidly generate reports.
Accessing
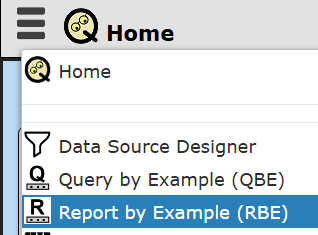
From the application Home tool RBE is accessible as shown below.

Alternatively you can open the tool from the hamburger  menu on each tool.
menu on each tool.
Pressing the control key during the menu click opens the tool in another tab.
Starships Examples
From the Data service dropdown choose

From the database dropdown choose

Choose a collection

The left hand area is updated with a general schema of the collection.
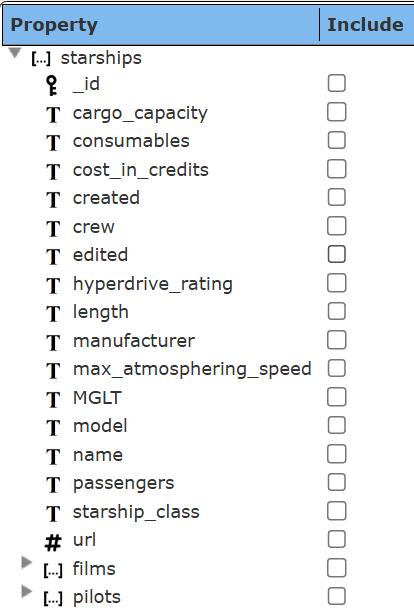
Click the name checkbox.

The middle area is updated to show your field selections and for optional criteria input.

The current query is also shown.

A rough template depiction is also shown.

Type in “asc”

The current query is updated.

Click  .
.
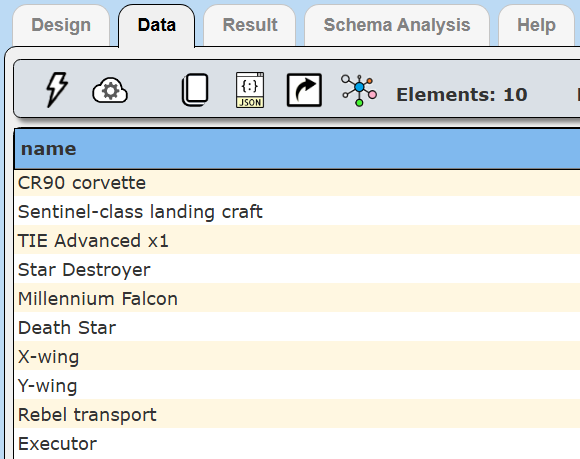
The query is run and the formatted results are shown.

Click the Data tab to see the underlying data retrieved.
Click back to the Design tab

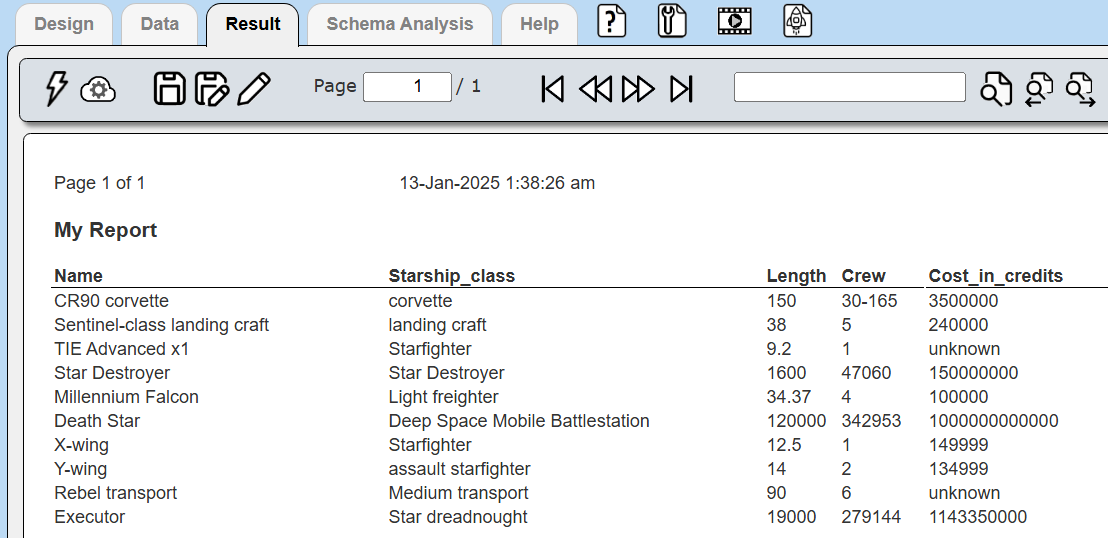
Select in this order starship_class, length, crew, and cost_in_credits.
The criteria area now looks like the following

Click
The result is shown below.
Click back to the Design tab
Click the ‘+’icon noted below.

Adjust the criteria so that the number of ships is shown and their total cost in credits.
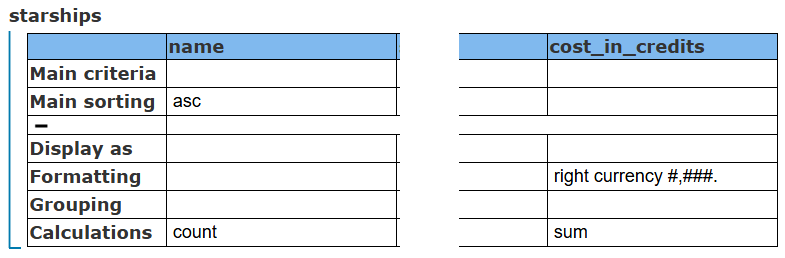
Cells are added to the template for these items as shown below.

Click
The result is shown below.
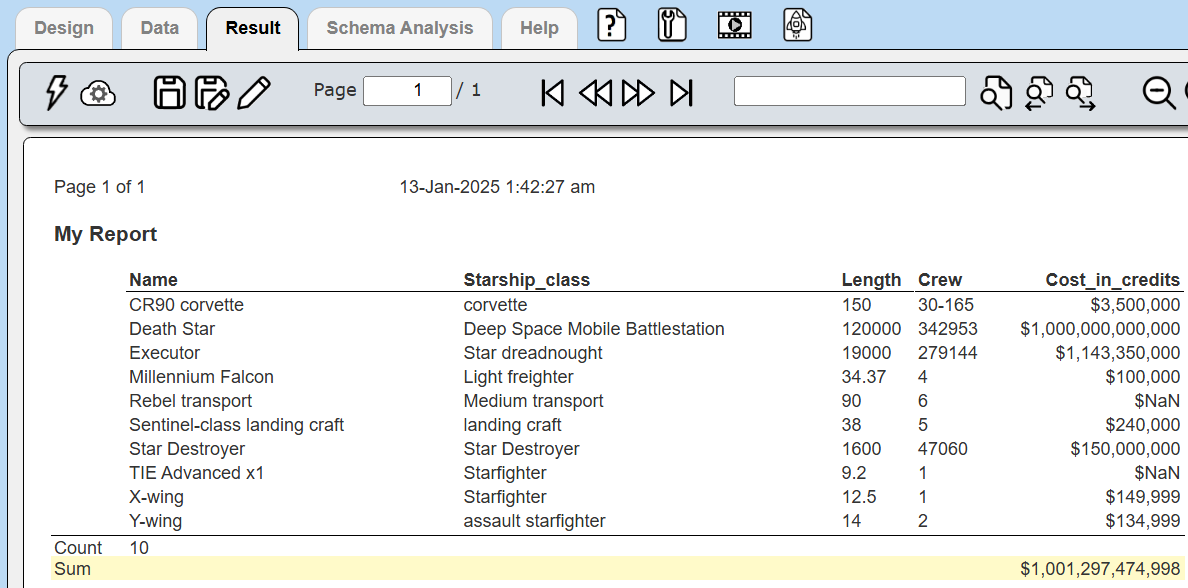
This example can be found at “example/Star Wars/Starships”.
Film Examples
Start a new component by clicking  .
.
Select the following drop down values.

Select Director, Release_date, Title and Producer.

The template is shown below.

Click
The result is shown below.

This example is saved as “films sorted by director”.
In the Design tab, click “+” and adjust the criteria as shown below.

The template is updated as shown below

Notice the directors are now group headings.
Click
The result is shown below.

This example is saved as “films grouped by director” by clicking

Do NOT do a “Save” because that replaces the current component which is likely the sort example!
Data Source Designer
References
On https://www.mongodb.com/basics/examples see the “Querying MongoDB Collections” section.
Overview
The Data Source Designer provides free form query input and result viewing.
Accessing
From the Home tool.

Alternatively you can open the tool from the hamburger menu on each tool.
Pressing the control key during the menu click opens the tool in another tab.
Some Examples
Choose the drop down values noted below.

To see the collections in the starwars database click as shown below.
A simple query is
db. people.find( { } )
The result column order is based on the answer set returned by the database. The ‘find” function has a query criteria argument (i.e., WHERE) and a projection (i.e., SELECT x,y) argument. More precise column ordering from MongoDB can be done using the MongoDB aggregation pipeline interface.
A query using the aggregation pipeline is ,
db. people.aggregate(
[
{$project: {_id: 0, name:1, height:1, mass: 1, birth_year: 1, films:1} } ,
{$sort: {name:1} }
]
)
Save this Data Source as “People sorted by name with films”.
Here is a query which unwinds an embedded array and looks up the referenced documents.
db. people.aggregate(
[
{$project: {_id: 0, name:1, height:1, mass: 1, birth_year: 1, films:1} } ,
{ $unwind: '$films' },
{$lookup : {from : 'films', localField: 'films', foreignField: '_id', as : 'films'}},
{$project: {name:1, height:1, mass:1,birth_year: 1, film: { "$arrayElemAt": [ "$films", 0 ] } } },
//{$project: {name:1, height:1, mass:1,birth_year: 1, "film.title": 1, "film.release_date": 1} },
{$sort: {name:1} }
]
)
Save this Data Source as “People sorted by name with films unwound and lookedUp”.
A sample find() query with a conditional is
db.starships.find(
{length: {$gt: 1000 } },
{_id:0, name:1, length:1, manufacturer: 1, starship_class: 1}
)
.sort( {length: 1} )
Save this Data Source as “Starships sorted by length” by clicking

Report Template Designer
Overview
The Report Template Designer provides a large variety of data processing, analysis, and presentation options. See its documentation for further details. From the Home tool open the tool by clicking the highlighted area below.

Alternatively you can open the tool from the hamburger menu on each tool.

. . .

Pressing the control key during the menu click opens the tool in another tab.
Some Examples
Starship Example
We can create a basic report for the starship information. The output is shown below.

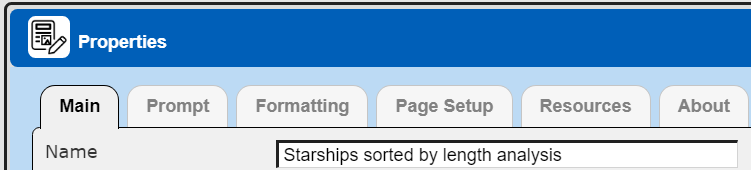
From a new template set the name to “Starships sorted by length analysis”. Next, we reference the Data Source named “Starships sorted by length”. This is done with the Properties dialog which is accessed by clicking

The main properties are shown below.
. . .

A basic template for the starship information is started by adding fields on the body line as shown below. The body has cells for each field value using the ‘=#PROPERTY” syntax such as “=#name”. The length cell is right justified.

Next the group header labels were added. This can be rapidly done by selecting each body cell, right clicking, and choosing.

The first two group header labels are shown below.

To get the underlines select the group header

On the right hand side choose the blackline shown below.

Finally, there is an average calculation on the group summary. To rapidly add the average length cell on the group summary, select the body cell ‘=#length’, right click, and choose

We add an “Average” label to the left of the average cell.
The template cells are shown below.
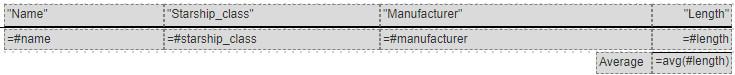
The execution output is shown below.

People with Unwound Films Example
We can create a basic report for the starship information. The output is shown below.
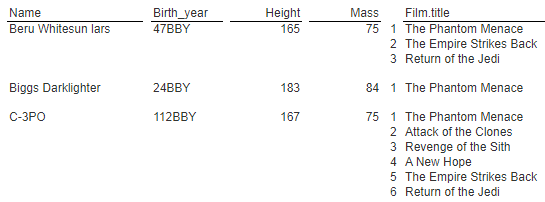
From a new template set the name to “People sorted by name with unwound films analysis”. Next, we reference the Data Source named “People sorted by name with films unwound and lookedUp”. This is done with the Properties dialog.
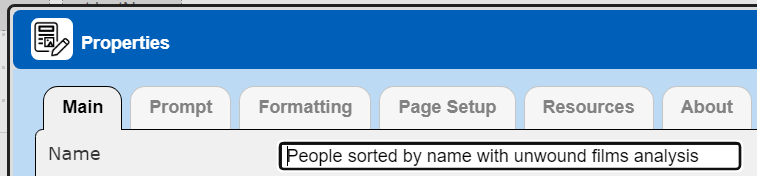
. . .

Recall that the query results unwound the embedded array. As a result our answer set list has rows looking like the following.

The only difference across each row is the film document. The first set of cells is shown below.

For this we will have body cells which are set to “Suppress duplicates”. Select the “=#name” cell

The right hand area toward the bottom shows.

Running this the output we get the results shown below.
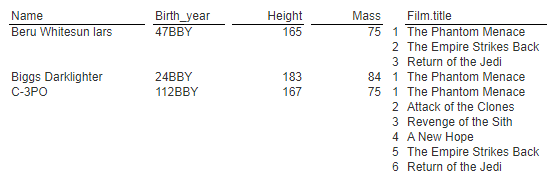
To get a spacer line between the people we insert a body line  above the single line. Select the new body line and see that it has a process condition as shown below.
above the single line. Select the new body line and see that it has a process condition as shown below.

As we iterate through the answer set a blank line will be output when the previous document’s name value is not the current document’s name. We use the documentProperty() function because the first time through there is no ‘@previous’ variable value.
To the left of the film name is a counter expression cell containing,
counter = if (@lastName = #name, @counter + 1, 1)
It is used with the cell to the right of the film name cell which tracks the last “people” name value. The result is a counter that is reset for each unique name,
The final analysis output is shown below.
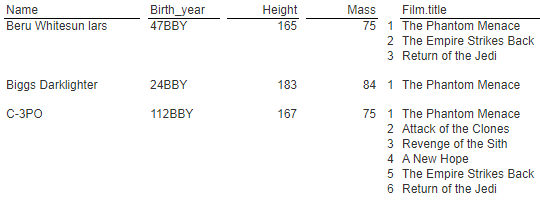
People with Dynamic Film Lookup
Recall the Data Source “People sorted by name with films” returns an answer set looking like the following.

Each document looks like the following.

Rather than unwinding the array and later using $lookup we can instead perform the film object loading within the analysis. This may be appropriate when there are multiple embedded arrays and we do not want to unwind each of them and cause a large expansion of answer set rows and byte size.
We will begin by saving the current “People sorted by name with films analysis” template into a new template with the name shown below.
. . .

. . .

Before going into the details, below is the initial output which has the film identifiers from the films embedded array.

For the analysis we place the people fields on the group header and iterate through the films within the body section. The final output is going to look like the following.

A summary of the group header cells can be seen by selecting the group header line.

Next, right click and choose

A summary of the line cells is shown in the dialog.

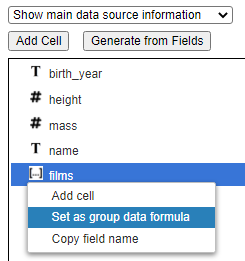
The “films” field is an embedded array. To drive its elements into the body and iterate through them we set the group’s properties as shown below.

To get this retrieval quickly set within the Template Designer, you can click on a free position within the body line, select the films field in the right hand area, and then choose the pop up menu option shown below.
To decode the film identifiers into film objects we can use Qarbine decode table which is created at the start of the execution.
The dynamic decode table is created on the report header line and its output is suppressed. It could also have been a report level calculation. Choose a free position on the report header and click the  button to open the Formula Editor. This dialog is also accessible by pressing control-E in many entry fields and text areas. Choose the area to show and then the specific macro function. The function’s usage will be shown. Clicking
button to open the Formula Editor. This dialog is also accessible by pressing control-E in many entry fields and text areas. Choose the area to show and then the specific macro function. The function’s usage will be shown. Clicking  will paste it into the text area for editing
will paste it into the text area for editing
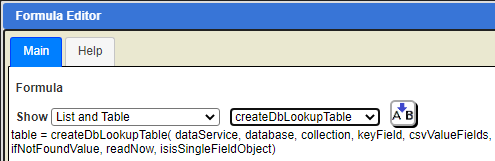
The cell formula is,
myTable = createDbLookupTable("Sample Data Service", "starwars", "films",
'_id', "title,release_date", documentAdd(), false, false)
This sets up the decode table to lookup a document in the films collection within the starwars database using the _id field. It returns a document with the title and release date fields. The cell’s output is suppressed as shown below

The body line has the following cells.
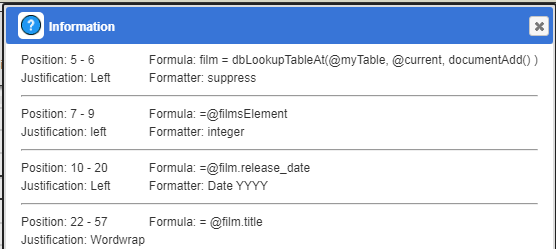
The first cell does the dynamic lookup using the current embedded films array identifier and sets the film variable. That output is suppressed.
To cross reference with the original report we display the film identifier.
To its right we display the film title and format the release date to show only the year.
The group header has the following cells.

The first group summary line has the cell which counts the number of films for the current people document.

The second group summary line is just a spacer line and has no cells.