Neptune Using Gremlin
Overview
Amazon Neptune is compatible with Apache TinkerPop3 and Gremlin. You can use the Gremlin traversal language to query Neptune. For differences in the Neptune implementation of Gremlin, see Gremlin standards compliance page found at
https://docs.aws.amazon.com/neptune/latest/userguide/access-graph-gremlin-differences.html.
Different Neptune engine versions support different Gremlin versions. Note that AWS Neptune provides both a Gremlin and a Neo4j semi-compatible Cypher interactions on the same underlying data. See the separate Qarbine Neo4j tutorial for that style of interfacing.
An excellent multi-series blog on Neptune querying can be found at https://aws.amazon.com/blogs/database/let-me-graph-that-for-you-part-1-air-routes/
Below is sample output from using Cypher to retrieve graph data and a Qarbine template to format the data.
Defining a Data Source
Overview
A Data Source is a Qarbine component responsible for retrieving data from somewhere. At a high level it has a name, a description and some arbitrary query string which when sent to the associated Qarbine Data Service endpoint returns some data. The overall execution flow for an analysis, including the optional prompt component, is shown below.

A single data source can be referenced by name from multiple Qarbine template components. This enables a single point of change when perhaps, an index is added, or some other query tweak is necessary. The alternative is to attempt to find all templates impacted by a schema or index change for example. The component reusability is especially beneficial when team members have varying roles and skills.
Below is the general schema of the sample European football league dataset.
 |  |
 |
The initial Cypher query is shown below.
MATCH (t:Team)
WHERE t.founded > 1900
OPTIONAL MATCH (t)-[:CURRENT_LEAGUE]->(league)
OPTIONAL MATCH (t)-[:STADIUM]->(stadium)
RETURN t, league, stadium
ORDER BY t.name
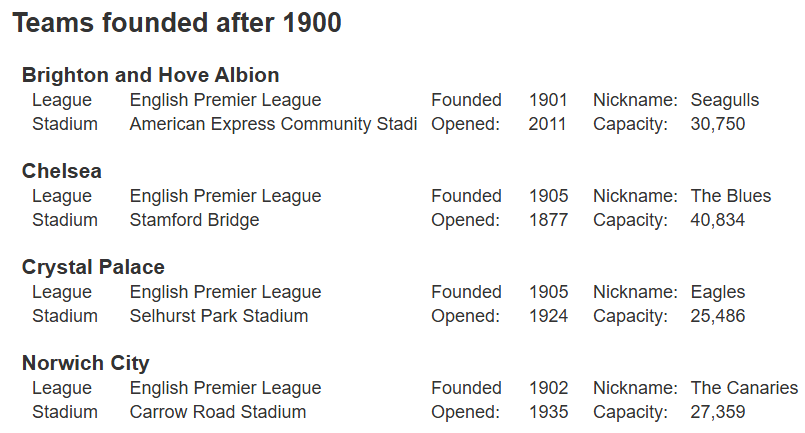
The results are shown below along with one of the elements selected.
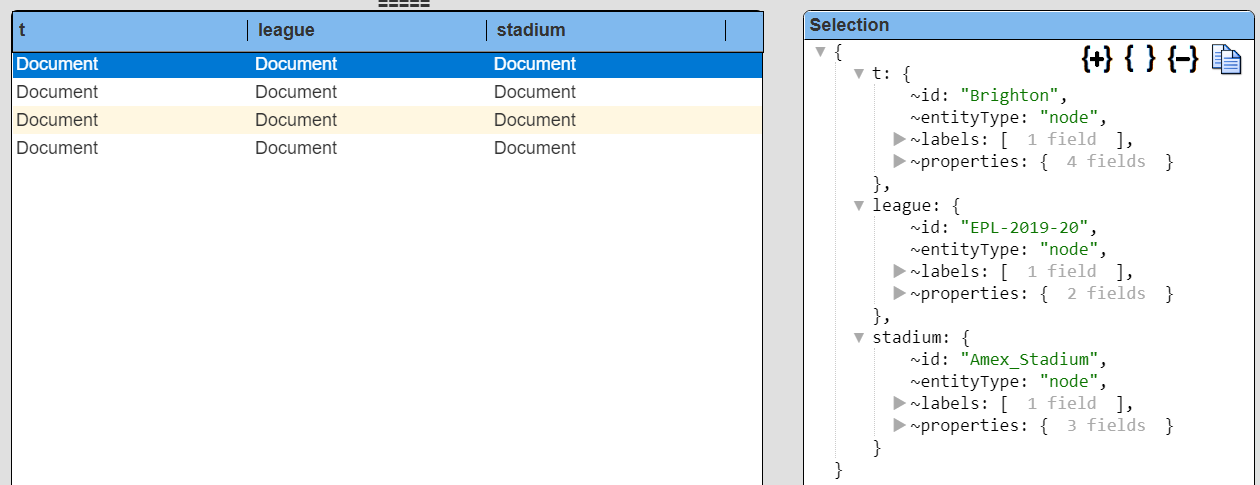
Using Qarbine pragmas the answer set will be simplified via
#pragma pullFieldsUp t
#pragma removeLeadingTildas league, stadium
#pragma removeRowLabels league, stadium
The updated results are shown below..
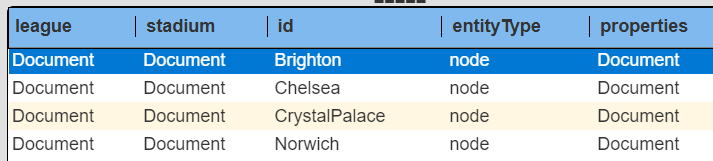
The updated element structure is shown below.
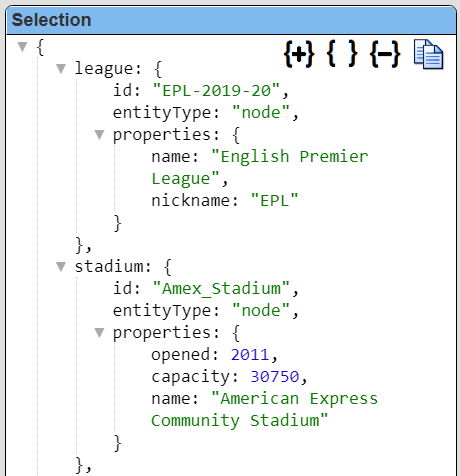 |  |
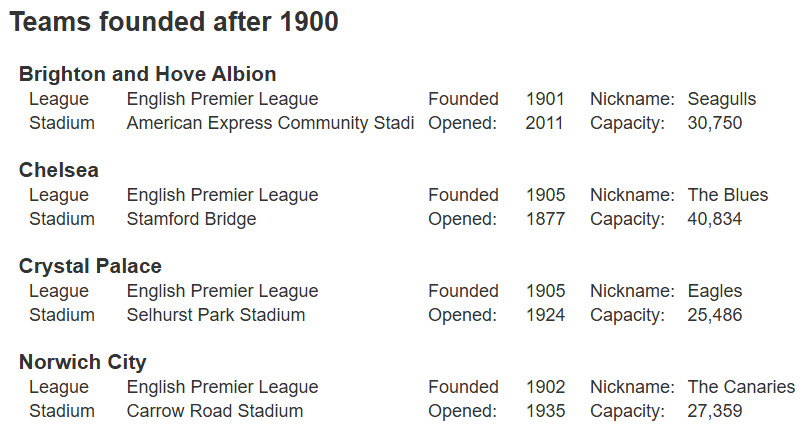
Rather than hard code the founding year, a variable can be used
#pragma pullFieldsUp t
#pragma removeLeadingTildas league, stadium
#pragma removeRowLabels league, stadium
MATCH (t:Team)
WHERE t.founded > @foundedAfterYear
OPTIONAL MATCH (t)-[:CURRENT_LEAGUE]->(league)
OPTIONAL MATCH (t)-[:STADIUM]->(stadium)
RETURN t, league, stadium
ORDER BY t.name
If you run this a default prompt appears for the variable value.
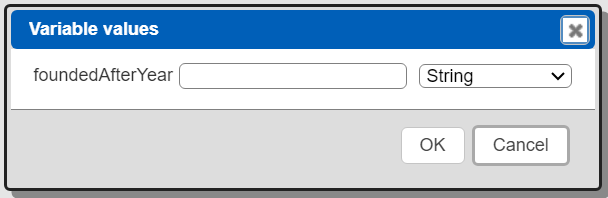
Fill in a year and adjust the data type.

To run the query click

The data source is in the catalog at “example/AWS/Neptune/All teams founded after @foundedAfterYear along with their related objects and pragmas”.
Managing Answer Set Size
The default maximum number of rows starts off at 25 for a new data source. This is useful to evolve a query from a concept to one that you have verified returns the desired answer set. As noted, any native way of limiting an answer set size is the preferred approach. This setting is in the component dialog as shown below and also accessible by clicking the ‘Gear’ icon.
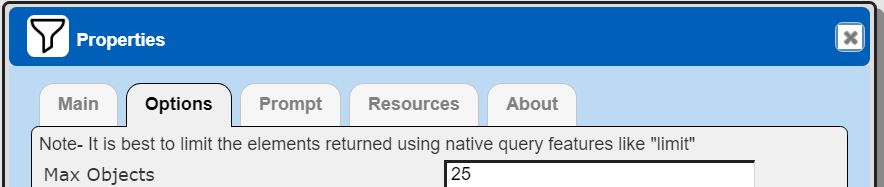
Once you are done drafting you can adjust this parameter. A “0” indicates there is no maximum. A number greater than 0 indicates to limit the final answer set size to that number of rows. This answer set truncation comes after any native query limit. So, if the answer set from the data endpoint is quite large, that content has to be returned to the Qarbine host. It then may truncate the number of rows. It is best to truncate at the query level (i.e., use a limit) to reduce the content sent from the data endpoint to the Qarbine host in the first place.
Adjusting the Maximum Rows
Recall the default maximum rows at the component level is 25. When you are satisfied with your query you can change that setting by clicking.

Adjust the setting to “0” indicating no Qarbine answer set truncation.

Click

Prompt Integration
Overview
Qarbine prompts provide a way to obtain runtime values and variables for data source and template execution. To avoid hardcoding, prompts can use macro formulas to run queries which populate list widgets. Prompts are defined in a no code manner using the Prompt Designer. Shown below is the execution flow when there is a Prompt component.

The Prompt Designer supports a large variety of input widgets including entry fields, check boxes, radio button groups, sliders, and file input.
Example
A Qarbine prompt component can be used to obtain runtime variables. In the following example it is used to obtain the foundedAfterYear value.
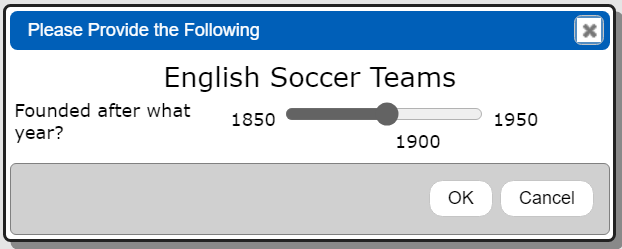
This prompt has 2 elements as shown below.

The second prompt element is defined as shown below.



The prompt is in the catalog at “example/AWS/Neptune/Prompt for Team @foundedAfterYear”.
Defining an Analysis Template
Overview
A template defines how to process the data being retrieved from Data Source queries and other data expressions. It also defines formulas, formatting options, and other analysis and presentation options. Team members can define templates which can be easily discovered by others for their running or to use as a starting point for other templates. The overall execution flow for an analysis, including the optional prompt component, is shown below

Example
Below is the sample template output.
The template’s main properties of interest are shown below.


When run the prompt referenced by the data source is presented to the user.
The answer set from the query has a few levels of objects. Formulas can use dot notation to reference the path to a value. A leading ‘#’ referenced a property while a leading ‘@’ references a variable.
| These formulas result in the same “Brighton and Hove Albion F.C” value: =@team.properties.fullName =#properties.fullName Likewise the league name formula is #league.properties.name The stadium name formula is #stadium.properties.name When many nested values of an object are going to be accessed then one technique is to define a suppressed cell to obtain the object and then use that object variable in subsequent cells. stadiumStuff = #stadium.properties = @stadiumStuff.founded = @stadiumStuff.fullName = @stadiumStuff.nickName | 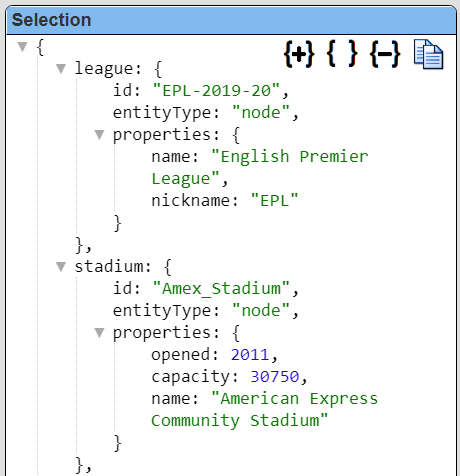  |
The general layout is shown below.
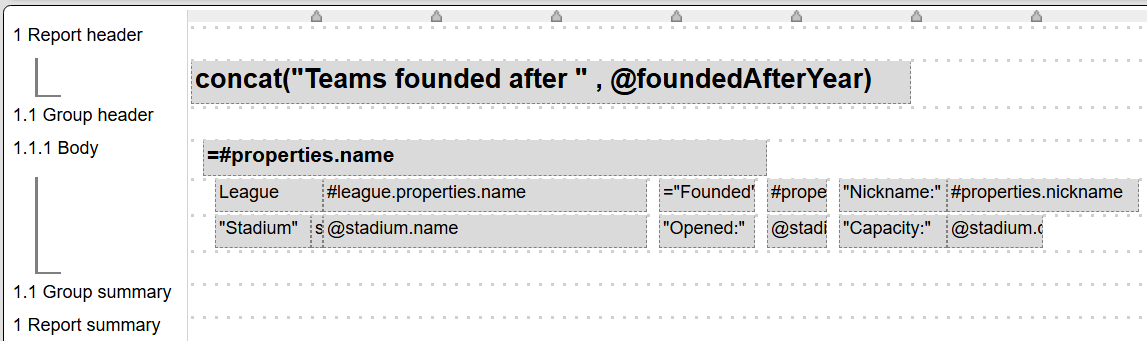
The report header cell uses a macro function to concatenate text with the foundedAfterYear variable obtained from the prompt.
The first body line has a bold cell to display the team name. The other body lines are described below.
| 2nd body line cells | 3rd body line cells |
|---|---|
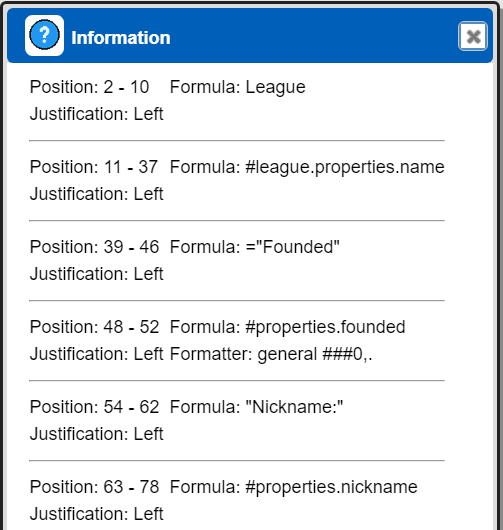 |  |
This template is in the catalog at “example/AWS/Neptune/All teams founded after prompted year along with their related objects and pragmas”.
Next Steps
Accessing Your Database
To configure access to your database see the guides at
Querying Your Database
For database specific interaction guides navigate to
References
https://aws.amazon.com/neptune/getting-started/https://kelvinlawrence.net/book/Gremlin-Graph-Guide.html
https://opencypher.org/