AI Assistant Configuration
Overview
Qarbine can use one of several Generative AI services to answer questions through “completions/inferences” and obtain embedding vectors. The latter can be used to locate similar content based on comparing their vectors in various vector savvy databases. Multiple “AI Assistants” can be configured within the same or across many Gen AI services.
ChatGPT, from the OpenAI company, is a natural language processing (NLP) tool driven by artificial intelligence that allows human-like conversations with a chatbot. The "GPT" stands for generative pre-trained transformer which is a type of large language model. The interface can answer questions and assist with tasks such as composing database queries. or summarizing text.
Several Qarbine GenAI integrated services follow the Open AI API interface pattern. These include:
- Open AI,
- Microsoft Azure Open AI,
- Mistral,
- Mixedbread AI (only embeddings),
- Fireworks AI,
- Friendly AI,
- Jina AI,
- Perplexity (only completions), and
- Voyage AI (only embeddings)
A similar set of functionality are available from these additional supported services:
- Anthropic (only completions),
- AWS Bedrock,
- Cohere,
- Google AI,
- Hugging Face,
- IBM Watsonx AI,
- Predibase (completions only), and
- Together AI.
The services which support multi-modal image embeddings include:
- AWS Bedrock and
- Hugging Face.
Portkey is an AI proxy service with observability features.
There are also databases such as MongoDB, Neo4j, Couchbase, Milvus, Weaviate, Qdrant, Chroma, LanceDB, and Pinecone which provide vector index searching that utilize embeddings. The configuration of each service is discussed in more detail below.
Related Qarbine Log Entries
If the AI Assistant plug-in is installed but there is no corresponding configuration information set by the Qarbine administrator then the following log entry is created in ˜./pm2/logs/main-out.log
AI Assistant- Requires System.servicesOnly setting of aiAssistants. There may be a syntax error.
AiAssistantFunctions postStartup AI Assistant. The plugin settings must be an array.
Please see the configuration documentation.
AI Assistant 1.0 AI Assistant. The plugin settings must be an array. Please see the configuration documentation.
Qarbine Administration Tool Interactions
Qarbine supports multiple AI endpoints including Open AI, Azure AI, Google AI, and AWS Bedrock. To configure Qarbine access to your AI endpoints, open the Qarbine Administration tool.
Click on the Settings tab.

Expand the row by clicking the highlighted arrow.

Right click and choose

Scroll down to the new entry.
The general form of this setting is
aiAssistants = [
{ entry 1 },
{ entry n }
]
There is only one setting for the “aiAssistants” variable. You define as many AI endpoints as appropriate and then refer to them by their alias. Qarbine supports multiple simultaneous AI assistants. Users are presented with the configured alias names for selection. A single Gen AI endpoint service can have multiple entries (with different aliases!) and use varying models and other settings across them.
The result of the expression MUST be an array. The entry structures vary by type of the endpoint as described in more detail below.
"alias" : "userFacingName",
"type" : "string", ← See below for possible values.
"active" : true | false, ← The default is true.
"isDefault" : true | false ← The default is false.
"model1" : "string",
"model2" : "string",
"temperature" : number,
"topK" : number,
"topP" : number,
. . .
The recognized type values are "AzureAI", "OpenAI", "AWS_Bedrock", “GoogleAI”, “Together”, “Gradiant”, and “GeneralAI”. The fields with “model1” refer to completion (completion/inference) oriented parameters while fields with “model2” refer to embedding parameters. The ‘model3’ parameters refer to image embeddings. For completions (inferences) the following parameters are commonly available.Refer to each specific service for details.
| Parameter | Comments |
|---|---|
| temperature | Adjusts the “sharpness” of the probability distribution. Higher temperature (greater than 1) results in more randomness, lower temperature (value closer to 0) results in more deterministic outputs. The default is 20. |
| topK | Restricts the model to pick from k most likely words, adding diversity without extreme randomness. The value of k may need to be adjusted in different contexts. Common values are in the range of 40-100. The default is 1. |
| topP | Restricts the model to pick the next word from a subset of words where the cumulative probability is just below p. This completion may add diversity than top-k because the number of words considered can vary. P is a float between 0-1, and in practice it is typically between 0.7-0.95. The default is 0.7. |
| maxGenerated TokenCount | Restricts the response to the given number of tokens. For AWS Bedrock this is the maxTokenCount parameter. |
| otherOptions1 | JSON of anything else to add to the payload for an completion endpoint. The default endpoint arguments are the messages and model. Common option field names are request_timeout, timeout, max_tokens, temperature, frequency_penalty and presence_penalty. |
The common embedding options are shown below.
| baseURI2 | The default for baseURI2 is the baseURI1 value. |
|---|---|
| otherOptions2 | The JSON for anything else to add to the payload for an embedding endpoint. The default arguments are input and model. |
Important Considerations
Editing
The standard setting listing is somewhat small for this setting so click inside the entry field and then press control-E to open up a larger editor.
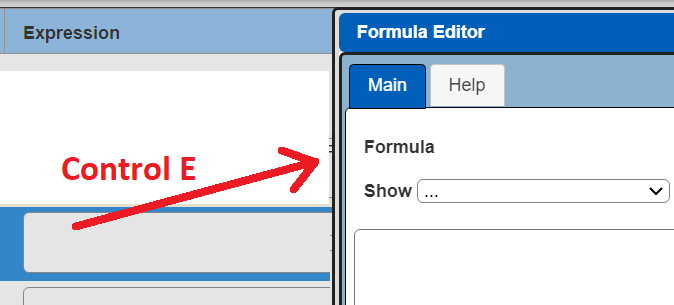
Alias Naming
The alias value must not have any spaces. Use camelcase style (helloWorld) for multiple word aliases.
Data Structure Sharing for Query Definition Interactions
For the Data Access AI Assistant ONLY your data structure information is sent to the endpoint which is fundamentally needed when it is being asked to format a query for data or explain an existing query. None of your underlying data itself is sent to the endpoint as part of the prompting context. Users must still be cautious about their free form input which is sent to the endpoint as part of the interaction lifecycle.
Broader Information Sharing
The display of query results and template generated report results provide options to interact with an AI Assistant. The general dialog is shown below.
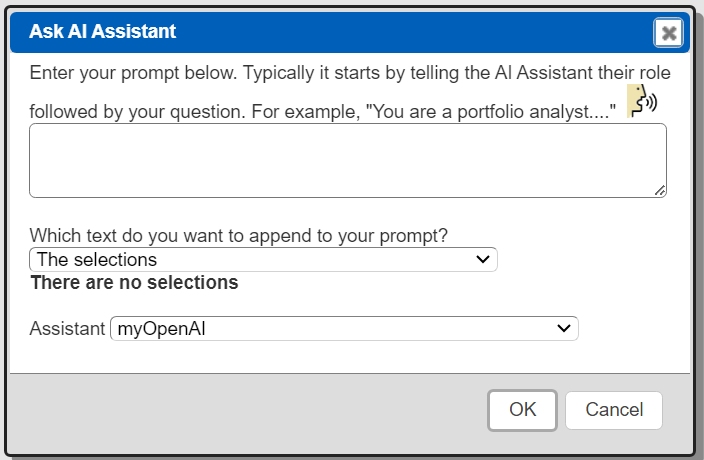
For query results the toolbar menu option is highlighted below.

The text options are shown below.

For template results the toolbar menu option is highlighted below.

The text options are shown below.
The template and query results may have content that your company policy does not want to be sent to a 3rd party AI service. The setting below controls access to these menu options.
allowResultInteractionsWithAiAssistant = false
It is defined within the Administration Tool’s Settings tab. Define the value in the section shown below.

The default is false. A sample entry enabling it is shown below.

End user interactions to Qarbine endpoints are logged for Qarbine Administrator review. This includes the AI Assistant service functionality. End user browsers are only presented with the AI Assistant aliases, types, and their default status.
Embedding Cache Parameters
The embedding values for a given AI Assistant are generally constants for a given model. These values which are arrays of floating point numbers can be optionally cached by Qarbine to avoid consumption of your endpoint tokens. The syntax for these settings is shown below.
aiAssistants = [
{option: 'cacheEmbeddings', value: true},
{option: 'maxCacheTextEmbeddingLength' , value: 90},
{ entry 1
{option: 'cacheEmbeddings', value: true},
},
{ entry n }
]
There is a global cacheEmbeddings setting and optionally a per entry cacheEmbeddings setting. The cache is within the Qarbine host’s folder ˜/qarbine.service/aiAssistant.
Open AI Configuration
Overview
The Qarbine Administrator must set the Open AI API key in the Qarbine Administration tool.
All interactions with OpenAI use their built-in moderation filters by prefixing prompts with “content-filter-alpha”. For more information see the details at https://platform.openai.com/docs/guides/moderation. There are considerations such as rate limits which can be reviewed at https://platform.openai.com/docs/guides/rate-limits. To view an account’s usage status visit the OpenAI website at https://openai.com/ and log in to your account using the credentials you used during the registration process. Once you are logged in, navigate to your account dashboard. OpenAI tokens are consumed by the API key’s organization.
See https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
and https://learn.microsoft.com/en-us/azure/ai-services/openai/overview#tokens.
Open.ai Console Interactions
See the Open AI website for details on obtaining an API key. A starting page is at https://openai.com/blog/openai-api.
Qarbine Administration Tool Interactions
To configure Qarbine access to the Open AI endpoint, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the entry as shown below.
"type": "OpenAI",
"alias" : "myOpenAi",
"isDefault" : true,
"baseURI1" : "YOUR_BASE_URI",
"apiKey" : "YOUR_API_KEY",
"model1" : "YOUR_INFERENCE_MODEL",
"model2" : "YOUR_EMBEDDING_MODEL",
"path1" : "SUBPATH_COMPLETION",
"path2" : "SUBPATH_EMBEDDING"
The default baseURI1 (you, are, eye, one) value is https://api.openai.com.
The model1 value for inferences (completions) is optional, The default is gpt-3.5-turbo.
See https://platform.openai.com/docs/api-reference/making-requests. Specify ‘None’ to not pass it as a payload argument with the input. This can be the case when path1 has the model within it.
The model2 value for embeddings is optional, The default is text-embedding-ada-002.
See https://platform.openai.com/docs/guides/embeddings. Specify ‘None’ to not pass it as a payload argument with the input. This can be the case when path2 has the model within it.
If the model is part of the path (path1 or path2) then use 'None' as the specification value.
The optional path1 is appended to the baseURI1 value to form the final HTTP endpoint. The optional path2 is appended to the baseURI1 value to form the final HTTP endpoint. These can be left out for standard Open AI interactions.
There are 2 endpoint options that are primarily used for Open AI compatible services as described below. The default endpoint1 for completions is /v1/chat/completions. The default endpoint2 for embeddings is /v1/embeddings.
To save this click

The API key is only visible within the Qarbine compute nodes. It is not visible in client browsers. The setting does not take effect until the next restart of the compute node with the Qarbine AI Assistant plugin. On the main Qarbine compute node, the plugins to load are listed in the file ˜/qarbine.service/config/service.NAME.json.
Open AI Compatible Services
Overview
Some 3rd parties offer Open AI API compatible services. These use a different base URI than the default Open AI one. When using such services be sure to set the baseURI1, model1 and model2 values appropriately for the 3rd party compatible service. A model1 value of 'default' passes no model at all to the completion service.
The apiKey and baseURI1 values are used for completions and the apiKey2 and baseURI2 values are used for embeddings. The default baseURI2 is whatever the value is for baseURI1.
A portion of a Mistral AI example specification is shown below.
{
"type" : "GeneralAI",
"alias" : "myMistral",
"isDefault" : true,
"apiKey" : "YOUR_API_KEY***",
"model1" : "pixtral",
"baseURI1" : "https://api.mistral.ai",
}
For clarity, the last entry is “base you are eye one”. Verify the use of commas separating the values and there is no trailing extra comma from a JSON perspective.
DeepSeek AI
DeepSeek AI offers an open source chat completion service using an API format compatible with OpenAI. Details on DeepSeek AI integration can be found at https://api-docs.deepseek.com/ .
A prerequisite is to obtain an API key from Deep Seek AI. To create an API key log on and then navigate to the page using the option highlighted below.

Click

Enter a name

Click

Click the Copy button shown below.

Paste the key into a temporary location.
Sample Qarbine parameters are shown below,
{
"type" : "OpenAI",
"alias" : "myDeepSeek",
"baseURI1" : "https://api.deepseek.com/v1",
"apiKey" : "YOUR_API_KEY",
"model1" : "deepseek-chat",
},
For a list of models and related pricing see https://api-docs.deepseek.com/quick_start/pricing
The deepseek-chat model has been upgraded to DeepSeek-V3. You can invoke DeepSeek-V3 by specifying a model1 of 'deepseek-chat'. The deepseek-reasoner is the latest reasoning model, DeepSeek-R1. You can invoke DeepSeek-R1 by specifying a model1 of 'deepseek-reasoner'.
Some references are
https://api-docs.deepseek.com/quick_start/parameter_settings
and
https://api-docs.deepseek.com/api/create-chat-completion
Fireworks AI
General information can be found at https://fireworks.ai/. The API Key can be found in your cloud console at https://fireworks.ai/api-keys. Sample parameters are shown below.
"baseURI1" : "https://api.fireworks.ai/inference",
"alias" : "myFireworks",
"apiKey" : "YOUR_API_KEY",
"model1" : "accounts/fireworks/models/llama-v2-7b-chat",
"model2" : "intfloat/e5-mistral-7b-instruct"
A listing of models can be found at https://fireworks.ai/models.
Friendli AI
General information can be found at https://friendli.ai. Qarbine uses the Friendli Open AI compatible interaction. Use the following basic values:
"type" : "GeneralAI",
"alias" : "myFriendli",
"apiKey" : "YOUR_API_KEY",
"baseURI1" : "https://inference.friendli.ai",
"model1" : "meta-llama-3-8b-instruct”
Your Friendli API keys can be found at https://suite.friendli.ai/user-settings/tokens.
The available models can be found at https://friendli.ai/models and vary by type of endpoint (serverless, dedicated, containerized).
Jina AI
General information can be found at https://jina.ai/. Jina.ai has different keys and base URI values for completions vs. embeddings so the apiKey2 parameter is used. Sample parameters are shown below.
"alias" : "myJina",
"apiKey" : "YOUR_API_KEY",
"apiKey2" : "YOUR_EMBEDDING_API_KEY",
"baseURI1" : "https://api.chat.jina.ai",
"baseURI2" : "https://api.jina.ai"
A tutorial on using Jina.ai can be found at https://www.mongodb.com/developer/products/atlas/jina-ai-semantic-search/
Mistral AI
General information can be found at https://mistral.ai/. Information on the Mistral API can be found at https://docs.mistral.ai/api/.
Use the following endpoint values:
"alias" : "myMistral",
"baseURI1" : "https://api.mistral.ai",
Information on the supported models can be found at https://docs.mistral.ai/models.
For the completion interactions additional otherOptions1 values to consider are safe_prompt and random_seed. Do not specify “stream: true”!
Mixedbread AI
Mixedbread only supports embeddings at this time. General information can be found at https://mixedbread.ai/. Information on the API can be found at https://www.mixedbread.ai/api-reference/endpoints/embeddings#create-embeddings.
Use the following basic values:
"type" : "GeneralAI",
"alias" : "myMixedbread",
"apiKey" : "YOUR_API_KEY",
"baseURI2" : "https://api.mixedbread.ai",
Model information can be found at https://www.mixedbread.ai/docs#what-are-embeddings
A sample embedding model value is
To obtain your API key navigate to https://www.mixedbread.ai/dashboard/user
Click on

to view the page.

Use an existing API key string or create a new one as desired.
Nomic AI
General information can be found at https://nomic.ai. Nomic only supports embeddings at this time. The required Nomic API key can be accessed by signing on to your Nomic dashboard at https://atlas.nomic.ai/ and then clicking the “API KEYS” tab. For documentation see https://docs.nomic.ai/index.html. Use the following setting values:
"type" : "GeneralAI",
"alias" : "myNomic",
"baseURI1" : "None",
"baseURI2" : "https://api-atlas.nomic.ai",
"path2" : "/v1/embedding/text",
"path3" : "/v1/embedding/image",
"apiKey" : "YOUR_NOMIC_KEY",
"model1" : "None", ← No completion support.
"model2" : "nomic-embed-text-v1",
"model3" : "nomic-embed-vision-v1.5",
"embedWhatField" : "texts"
The embedWhatField is required. If it is missing then Nomic raises an error “error 422 Unprocessable Entity.Error”.
Perplexity AI
General information can be found at https://perplexity.ai. Perplexity only supports completions at this time. For information on available models see https://docs.perplexity.ai/docs/model-cards. A discussion of them is at https://blog.perplexity.ai/blog/introducing-pplx-online-llms. Use the following basic setting values:
"type" : "GeneralAI",
"alias" : "myPerplexity",
"baseURI1" : "https://api.perplexity.ai",
"endpoint1" : "/chat/completions", ← Different than the Open AI default.
A sample completion model value is
"model1" : "llama-2-70b-chat",
Since Perplexity does not support embeddings, set this parameter,
"baseURI2" : "None",
Some otherOptions1 parameters to consider are presence_penalty and frequency_penalty. For API details see https://docs.perplexity.ai/reference/post_chat_completions.
Upstage AI
General information on Upstage AI can be found at https://www.upstage.ai.
Use the following basic values:
"type" : "GeneralAI",
"alias" : "myUpstage",
"apiKey" : "YOUR_API_KEY",
"baseURI1" : "https://api.upstage.ai",
"path1" : "/v1/solar/chat/completions",
"path2" : "/v1/solar/embeddings",
"model1": "solar-1-mini-chat",
"model2": "solar-embedding-1-large-query",
Your Upstage API keys can be found at https://console.upstage.ai/api-keys. Use an existing one or create a new one as required.
The available Solar LLM models can be found at https://developers.upstage.ai/docs/getting-started/models.
Voyage AI (Now part of MongoDB)
Voyage AI only supports embeddings at this time. General information can be found at https://voyageai.com.
Information on the API can be found at https://docs.voyageai.com/docs/embeddings
Use the following basic values:
"type" : "GeneralAI",
"alias" : "myVoyage",
"apiKey" : "YOUR_API_KEY",
"baseURI2" : "https://api.voyageai.com",
Model information can be found at https://www.mixedbread.ai/docs#what-are-embeddings
A sample embedding model value is
To obtain your API key navigate open your Voyager dashboard at https://dash.voyage.com.
Navigate to the API key page by clicking

Use an existing key or create a new one by clicking

Follow the prompts to obtain your API key.
Anthropic AI
Overview
Anthropic only provides completion support. See https://www.anthropic.com/ for more geneal information and the following for embeddings information https://docs.anthropic.com/claude/docs/embeddings.
Anthropic Configuration
Sign into your Anthropic account.
Navigate to the following page to obtain an API key.
Click

Enter a name for the key.

Click

A dialog appears.
Click

Click

Qarbine Administration Tool Interactions
To configure Qarbine access to the Anthropic AI endpoint, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the value template shown below.
"type": "Anthropic",
"alias" : "myAnthropic",
"apiKey" : "YOUR API KEY",
"model1" : "YOUR COMPLETION MODEL",
The default for model1 is “claude-2.1” and the default maxTokens is 1024.
To save this click
The API key is only visible within the Qarbine compute nodes. It is not visible in client browsers. The setting does not take effect until the next restart of the compute node with the Qarbine AI Assistant plugin. On the main Qarbine compute node, the plugins to load are listed in the file ˜/qarbine.service/config/service.NAME.json.
Azure Cognitive Services Configuration
Overview
For more information see https://azure.microsoft.com/en-us/products/ai-services/openai-service and https://learn.microsoft.com/en-us/azure/ai-services/openai/quickstart.
You need several parameters to interact with the Azure Open AI services,
| Parameter | Comments |
|---|---|
| Endpoint | This value can be found in the Keys & Endpoint section when examining your resource from the Azure portal. Alternatively, you can find the value in the Azure AI Studio > Playground > Code View. An example endpoint is: https://docs-test-001.openai.azure.com/ where “docs-test-001” is the name of the Azure resource. |
| API key | This value can be found in the Keys & Endpoint section when examining your resource from the Azure portal. You can use either KEY1 or KEY2. |
| Deployment ID | This is the name of your deployed model. |
Azure Portal Interactions
Endpoint and API Key Determination
Sign on to portal.azure.com. On the home page search for “openai” as shown below.
Click the gray area to open the Azure AI services page.
If you have no OpenAI deployments then you will be presented with that status.
Creating an OpenAI Deployment
If there are none then the first time through click the button shown below.
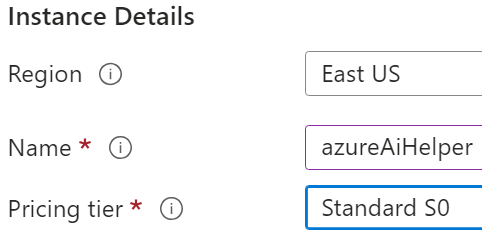
Fill in the fields.

…
Click

Choose your network configuration.

Click
Set any tags.

Click
Review the settings.
Click

Wait

Soon you will see

Click

Accessing the API Keys
On the right hand side of the page note the endpoint URL.

Click the highlighted link

This opens the page with the heading similar to the one below.

The resource name in this example is “azureaihelper”.
Note the fields below.
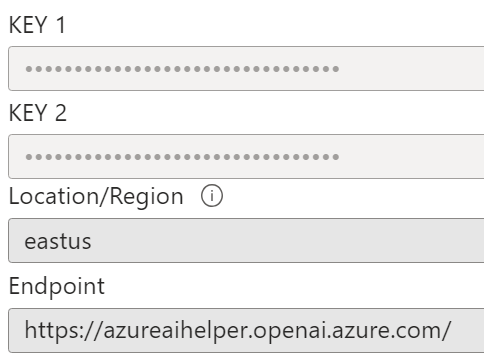
Copy one of the KEY values by clicking on  .
.
Store it somewhere temporarily.
Copy the endpoint by clicking on  . For example,
. For example,
Also store it somewhere temporarily. You will need your endpoint and access key for authenticating your Azure Open AI requests by Qarbine.
First Model Deployment Creation
A model is required by the OpenAI service. In the left hand gutter area click

Note the message

Click

If you have none then the first time through you will see

Click

Fill in the fields
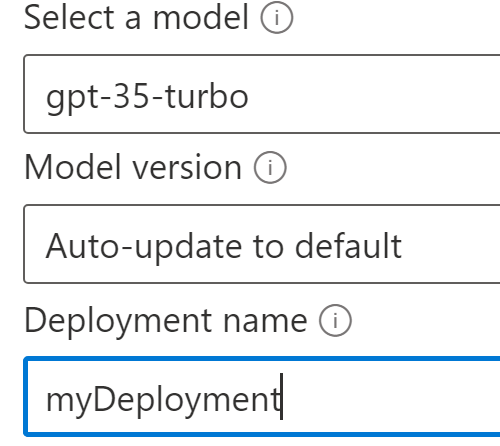
Note the deployment name. It is needed for Azure Open AI interactions by Qarbine.
Click

You should then see

The page updates to show the deployment.

A separate deployment is required for the Qarbine embedding support. The Qarbine macro function embeddings(string) returns the vectors for the given string. These vectors can subsequently be used in a vector aware query,
Based on the steps above, create another deployment using the text-embedding-ada-002 model.
Shown below are 2 sample deployments in the azureaihelper named resource.

Together.ai Configuration
Overview
The interaction with Together.ai is only for obtaining vector embeddings.
Detailed information can be found at Together.ai. Evaluation accounts can be signed up for at https://api.together.xyz/signup. For information on their Open AI API compatibility see https://docs.together.ai/docs/embedding-openai-api-compatibility. A discussion of using Together.ai and MongoDB can be found at https://www.together.ai/blog/rag-tutorial-mongodb.
For more information see https://docs.together.ai/docs/embedding-openai-api-compatibility
You need several parameters to interact with the Together.ai services,
| Endpoint | This value is https://api.together.xyz/v1. |
|---|---|
| API key | This value can be found on https://api.together.xyz/settings/api-keys. |
| Model | Information on the various available models can be found at https://docs.together.ai/docs/embedding-models. An example is "togethercomputer/m2-bert-80M-2k-retrieval". |
Qarbine Administration Tool Interactions
To configure Qarbine access to the AI endpoint, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the value template shown below.
"type": "AzureAI",
"alias" : "myAzure",
"isDefault" : true,
"apiKey" : "YOUR API KEY",
"resource1" : "YOUR COMPLETION RESOURCE",
"deployment1" : "YOUR COMPLETION DEPLOYMENT",
"resource2" : "YOUR EMBEDDING RESOURCE",
"deployment2" : "YOUR EMBEDDING DEPLOYMENT"
In our example the completion and embedding resource names are the same.
To save this click
The API key is only visible within the Qarbine compute nodes. It is not visible in client browsers. The setting does not take effect until the next restart of the compute node with the Qarbine AI Assistant plugin. On the main Qarbine compute node, the plugins to load are listed in the file ˜/qarbine.service/config/service.NAME.json.
AWS Bedrock Configuration
Overview
To read about embeddings in AWS Bedrock see
https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html
The completion model used is anthropic.claude-v2. Its parameters include a maximum of 5000 tokens, temperature of 0.5, and top_k of 250.
The embedding model used is “amazon.titan-embed-text-v1”. For embedding configuration see
https://docs.aws.amazon.com/bedrock/latest/userguide/embeddings.html.
Accessing the Model
For the completion service you must have access to the AWS Claude Anthropic model. Navigate to
Click
Getting Started
At the prompt
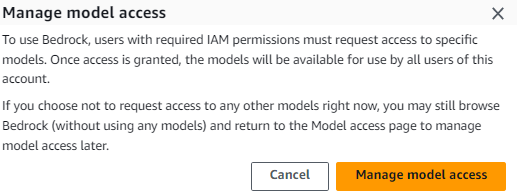
Click
Manage model access
Click

Click

Fill in your details in

Apply LLMs to the broad use case of helping to query AWS NoSQL databases and help author AWS NoSQL database queries. We also integrate with legacy SQL databases. Qarbine amplifies customer ROI for AWS NoSQL databases by providing a suite of analysis and reporting tools which are modern data savvy.
Click

Review

Click

Click

Wait

Click

If necessary, wait for the model to be available. Once the model is available in Bedrock, you can use it to play around in the AWS console with Chat, Text and Image sections, depending on the requested model. You can also configure Qarbine’s interaction.
For embedding, you must have access to the amazon.titan-embed-text-v1 model.
See https://docs.aws.amazon.com/bedrock/latest/userguide/embeddings.html.
Defining AWS IAM Credentials
Use AWS Identity and Access Management (IAM) to create a user with Bedrock access. The associated sample policy details are shown below.

Next, obtain the AWS access key ID and secret access key credentials to configure Qarbine to interact with Bedrock.
Qarbine Administration Tool Interactions
To configure Qarbine access to the Azure Open AI endpoint, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the value template shown below.
"type": "AWS_Bedrock",
"alias" : "myBedrock",
"isDefault" : true,
"accessKeyId" : "AKIA******",
"secretAccessKey" : "8QRXh2*****",
"region" : "us-east-1",
"model1": “xxx”, ← The completion default is "anthropic.claude-v2".
"maxTokensToSample" : number,
"model2": “yyy”, ← The embedding default is "amazon.titan-embed-text-v1".
"model3": “yyy”, ← Image embedding default is “amazon.titan-embed-image-v1".
For information on model parameters see:
To save this click
The AWS credentials are only visible within the Qarbine compute nodes. They are not visible in client browsers. The setting does not take effect until the next restart of the compute node with the Qarbine AI Assistant plugin. On the main Qarbine compute node, the plugins to load are listed in the file ˜/qarbine.service/config/service.NAME.json.
Cohere
Overview
For general information on Cohere see https://cohere.com/.
Cohere Portal Interactions
The Cohere API keys can be found within your account at
Qarbine Administration Tool Interactions
To configure Qarbine access to the endpoints, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the basic template shown below.
aiAssistants = [
{
"type": "Cohere",
"alias" : "myCohere",
"apiKey" : "YOUR API TOKEN"
}
]
The default baseURI1 is "https://api.cohere.ai". Note there is no trailing slash.
The default for the completions model1 value is "/v1/generate". The default for the embedding model2 value is "/v1/embed". Note the leading slash.
The optional model1 is appended to the baseURI1 value to form the final HTTP endpoint. The optional model2 is appended to the baseURI1 value to form the final HTTP endpoint.
To save this click
The API key is only visible within the Qarbine compute nodes. It is not visible in client browsers. The setting does not take effect until the next restart of the compute node with the Qarbine AI Assistant plugin. On the main Qarbine compute node, the plugins to load are listed in the file ˜/qarbine.service/config/service.NAME.json.
Google AI (Gemini) Configuration
Overview
Google AI provides both completion and embedding services. The endpoints integrated into Qarbine use Gemini which is Google's largest and most capable AI model. For details see https://deepmind.google/technologies/gemini/#introduction.
Google Portal Interactions
The Google AI API keys can be obtained from Google AI Studio at the following URL,
https://makersuite.google.com/app/apikey. Details on the API can be found at https://ai.google.dev/docs.
Qarbine Administration Tool Interactions
To configure Qarbine access to the AI endpoint, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the value template shown below.
"type": "GoogleAI",
"alias" : "myGoogle",
"apiKey" : "YOUR API KEY",
"model1" : "YOUR COMPLETION MODEL",
"model2" : "YOUR EMBEDDINGS MODEL"]
The default baseURI1 value is "https://generativelanguage.googleapis.com/v1beta".
The list of Gemini models can be found at https://ai.google.dev/models/gemini. The default model1 value is "models/gemini-pro”. The default model2 value is “models/embedding-001”.
To save this click
The API key is only visible within the Qarbine compute nodes. It is not visible in client browsers. The setting does not take effect until the next restart of the compute node with the Qarbine AI Assistant plugin. This can be done from the Qarbine Administrator tool. On the main Qarbine compute node, the plugins to load are listed in the file ˜/qarbine.service/config/service.NAME.json.
Gradient Configuration
Overview
Gradient provides both general purpose and industry specific large language models. In addition, it can manage private models. For more information see https://gradient.ai/.
Gradient Portal Interactions
The Gradient access token and workspace identifiers required by the Qarbine configuration can be found on the page at https://auth.gradient.ai/select-workspace
Qarbine Administration Tool Interactions
To configure Qarbine access to the AI endpoint, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the value template shown below.
aiAssistants = [
{
"type": "Gradient",
"alias" : "myGradient",
"isDefault" : true,
"apiKey" : "YOUR ACCESS TOKEN",
"workspace" : "YOUR WORKSPACE_ID",
"model1" : "YOUR COMPLETION MODEL",
"model1Format" : "MODEL_FORMAT",
"model2" : "YOUR SLUG ID",
}
]
The value for model1 is the model identifier from the page at https://docs.gradient.ai/docs/models-1. Below are sample values from that page. The default is for the Llama-2 7B language model.
| Language Model | Model ID and Slug ID |
|---|---|
| Bloom-560 | 99148c6d-c2a0-4fbe-a4a7-e7c05bdb8a09_base_ml_modelbloom-560m |
| Llama-2 7B | f0b97d96-51a8-4040-8b22-7940ee1fa24e_base_ml_model Llama-2 13B |
| Nous Hermes 2 | cc2dafce-9e6e-4a23-a918-cad6ba89e42e_base_ml_modelnous-hermes2 |
The model1Format value is needed to properly format the request to match the appropriate base model used for fine-tuning. The following slightly generic values may be used: “Llama” and “Nous Hermes”. The default is ‘Llama’. For more information see https://docs.gradient.ai/docs/cli-quickstart#-generating-completions-from-your-model
The model2 value is used for embeddings. Its default value is “bge-large”.
In our example the completion and embedding resource names are the same.
To save this click
The API key is only visible within the Qarbine compute nodes. It is not visible in client browsers. The setting does not take effect until the next restart of the compute node with the Qarbine AI Assistant plugin. On the main Qarbine compute node, the plugins to load are listed in the file ˜/qarbine.service/config/service.NAME.json.
Hugging Face
Overview
For general information on Hugging Face see https://huggingface.co/.
Hugging Face Portal Interactions
The Hugging Face access tokens can be found within your account at https://huggingface.co/settings/profile.
Qarbine Administration Tool Interactions
To configure Qarbine access to the Hugging Face endpoints, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the value template shown below.
"type": "HuggingFace",
"alias" : "myHuggingFace",
"apiKey" : "YOUR ACCESS TOKEN",
"baseURI1" : "aaa",
"baseURI2" : "...",
"model1" : "the completion model",
"model2" : "the text embedding model",
"model3" : "the image embedding model",
The default baseURI1 is "https://api-inference.huggingface.co". Note there is no trailing slash.
The default for baseURI2 is the baseURI1 value.
The default for model1 is "/models/mistralai/Mistral-7B-v0.1". The default for model2 is "/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2". The default model3 is “/models/google/vit-base-patch16-384”. Note the leading slashes. The base URI values and these model values form the service call URL.
The default "otherOptions1"and "otherOptions2" value is {wait_for_model: true}. This is to reduce problems with an error such as {"error":"Model sentence-transformers/all-MiniLM-L6-v2 is currently loading","estimated_time":20.0}.
Observed Caveats
Depending on your subscription, you may receive
Model is too large to load onto the free Inference API. To try the model, launch it on
Inference Endpoints instead. See https://ui.endpoints.huggingface.co/welcome,
This is the case for a model such as gradientai/v-alpha-tross. Albatross is a collection of domain-specific language models for finance applications developed by Gradient. For blogs on this model see https://gradient.ai/blog/albatross-responsible-ai and
https://gradient.ai/blog/alphatross-llm-now-available-on-hugging-face.
With the completion URL "https://api-inference.huggingface.co/models/mistralai/Mistral-7B-v0.1" asking "What is the capital of France" returned
[{'generated_text': 'What is the capital of France?\n\nParis is the capital of France.\n\n
What is the capital of the United States?\n\nWashington, D.C. is the capital of the United
States.\n\nWhat is the capital of the United Kingdom?\n\nLondon is the capital of the
United Kingdom.\n\nWhat is the capital of Canada?\n\nOttawa is the capital of
Canada.\n\nWhat is the capital of Australia?\n\nCanberra is the capital of Australia'}]
Lower casing the country name and asking "What is the capital of france" returned
[{'generated_text': 'What is the capital of france?\n\nParis is the capital of France. It is
located in the north of the country, on the river Seine. It is the largest city in France, with
a population of over 2 million people. Paris is known for its beautiful architecture,
including the Eiffel Tower, the Louvre Museum, and the Arc de Triomphe. It is also a
major center for fashion, art, and culture.\n\nWhat is the capital of france in french?\n'}]
IBM Watsonx
Overview
IBM Watsonx provides both general purpose and industry specific large language models. For more information see https://www.ibm.com/products/watsonx-ai.
The following are needed in order to use the Watson AI embedding and completion services:
- Watson Studio project ID,
- API key and
- an associated service with an Editor role.
Background details on these values are in the separate document “IBM Watson AI Integration”.
Qarbine Administration Tool Interactions
To configure Qarbine access to the endpoints, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
The basic template for setting is shown below.
{
"type" : "IBMWatson",
"alias" : "myIBMWatson",
"apiKey" : "your_IBM_API_key",
"region" : "us-south",
"CRN" : "crn:v1:bluemix:public:lakehouse:us-south:...::",
"model1" :"google/flan-ul2",
"version1" : "2023-05-02",
"model2" :"sentence-transformers/all-minilm-l12-v2",
"project1" : "5c283fa8-...",
"version2" : "2024-03-14",
"project2" : "5c283fa8…",
}
The apiKey, region, CRN, and project1 values are required. The model1, version1 and project1 settings are for text completions. The model2, version2, and project2 values are for embeddings. The default for project2 is the value for project1. Shown above are the defaults for version1, model1, version2, and model2.
Portkey
Overview
Portkey provides an AI proxy with observability options. For general information on Portkey see https://portkey.ai/.
Portkey Portal Interactions
Sign on to your Portkey account at https://app.portkey.ai/.
There are two options for interacting with Portkey:
- virtual keys and
- configurations.
Virtual Key Usage
For information on using API keys see https://docs.portkey.ai/docs/api-reference/authentication.
To use a Portkey virtual key click on

Qarbine’s setup requires both your Portkey API key and the intended AI provider’s key. The former can be obtained simply by clicking  for the desired key. You will still need to locate your AI provider key.
for the desired key. You will still need to locate your AI provider key.
If you do not yet have an API key click

In the dialog enter a name for the key

Choose the provider

Enter your API key for the AI provider. You’ll also need this to configure Qarbine.

Click
Configuration
For information on using configurations see https://docs.portkey.ai/docs/product/ai-gateway-streamline-llm-integrations/configs
To use a Portkey configurations click on

Qarbine’s setup requires both your Portkey configuration ID and the intended AI provider’s key.
The former can be obtained simply by clicking for the desired configuration. You will still need to locate your AI provider key.
If you do not yet have an configuration click
Enter a name

Click

Qarbine Administration Tool Interactions
To configure Qarbine access to the endpoints, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
The basic template for setting is shown below.
{
"type" : "GeneralAI",
"alias" : "myPortkey",
"apiKey" : "yourOpenAiKey",
"otherHeaders1" : {
"x-portkey-provider" : "openai", ← See values below.
"x-portkey-api-key" : "yourPortkeyApiKey", ← This or the next line.
"x-portkey-virtual-key": "yourPortkeyVirtualKey",
"x-portkey-custom-host" : "http://MODEL_URL/v1/",
},
"baseURI1" : "https://api.portkey.ai",
"model1" : "OptionalCompletionModel",
"model2" : "OptionalEmbeddingsModel"
}
The provider values include ‘openai’, ‘anthropic’, ‘mistral-ai’, and ‘cohere’.
The x-portkey-custom-host header is for local or private models. For more details see https://docs.portkey.ai/docs/product/ai-gateway-streamline-llm-integrations/universal-api#integrating-local-or-private-models
There are 4 related headers that can be used:
- x-portkey-aws-session-token
- x-portkey-aws-secret-access-key
- x-portkey-aws-region
- x-portkey-aws-session-token
For further details see https://docs.portkey.ai/docs/welcome/integration-guides/aws-bedrock#making-requests-without-virtual-keys.
See the Portkey configuration documentation for more details at https://docs.portkey.ai/docs/welcome/integration-guides.
Predibase
Overview
For general information on Predibase see https://predibase.com/.
Predibase Portal Interactions
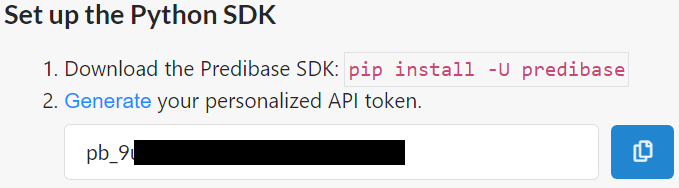
The Predibase API tokens can be found within your account by navigate to
Click

Copy the API token into a temporary area by clicking the button in the lower right below.
Locate your tenant ID by clicking

The tenant ID is shown to the right

Qarbine Administration Tool Interactions
To configure Qarbine access to the Predibase endpoints, open the Qarbine Administration tool as described at the top of this document. Create or edit the aiAssistants setting.
Check the Read only box and fill in the value template shown below.
"type" : "Predibase",
"alias" : "myPredibase",
"apiKey" : "YOUR_API_TOKEN",
"path1" : "/TENANT_ID/deployments/v2/llms",
"model1" : "mistral-7b-instruct-v0-2"
The default baseURI1 is "https://serving.app.predibase.com". Note there is no trailing slash.
The supported models can be found at
The default for model1 is "mistral-7b-instruct-v0-2".