DynamoDB
Summary
This document covers the information to gather from AWS and DynamoDB in order to configure a Qarbine data service. The data service will use the Qarbine DynamoDB driver. You can define multiple data services that access the same DynamoDB endpoint though with varying credentials. Once a data service is defined, you can manage which Qarbine principals have access to it and its associated DynamoDB data. A Qarbine administrator has visibility to all data services.
The example catalog components use a data service named “AWS DynamoDB”. To use them, create such a data service with your settings as described below.
Overview
DynamoDB is a fully managed NoSQL database running within AWS. For more details see https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html.
DynamoDB Configuration
Qarbine uses programmatic access to interact with DynamoDB. The Qarbine host must have network access to the DynamoDB endpoint and the Qarbione Data Service must be configured to have permissions to query the database. The permissions should be read-only in nature. A single Qarbine compute host can be configured to access multiple data services and those data services may each require differing AWS credentials. Each Qarbine data service is defined with the following parameters:
- access key ID,
- secret access key,
- region, and
- endpoint.
The general endpoint format is
https://dynamodb.{region}.amazonaws.com
A sample endpoint which is used as the Qarbine server template value is
https://dynamodb.us-east-1.amazonaws.com
The first 3 may be the same across data services depending on your deployment scenario and company policies. Use the AWS Identity and Access Management (IAM) console to configure access. When creating an access key in IAM the usage is generally,
“Application running on an AWS compute service
You plan to use this access key to enable application code running on an AWS compute service like Amazon EC2, Amazon ECS, or AWS Lambda to access your AWS account.”
The Qarbine Data Service privileges should just be AmazonDynamoDBReadOnlyAccess. For more information see
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SettingUp.DynamoWebService.html
Qarbine Configuration
Compute Node Preparation
Determine which compute node service endpoint you want to run this data access from. That URL will go into the Data Service’s Compute URL field. Its form is “https://domain:port/dispatch”. A sample is shown below.

The port number corresponds to a named service endpoint configured on the given target Qarbine host. For example, the primary compute node usually is set to have a ‘main’ service. That service’s configuration is defined in the ˜./qarbine.service/config/service.main.json file. Inside the JSON file the following driver entry is required
"drivers" :[
. . .
"./driver/dynamoDbDriver.js"
]
Remember to have well formed JSON syntax or a startup error is likely to occur. If you end up adding that entry then restart the service via the general command line syntax
pm2 restart <service>
For example,
pm2 restart main
or simply
pm2 restart all
Data Service Definition
Open the Administration Tool.
Navigate to the Data Services tab.

A data service defines on what compute node a query will run by default along with the means to reach to target data. The latter includes which native driver to use along with settings corresponding to that driver. Multiple Data Sources can reference a single Data Service. The details of any one Data Service are thus maintained in one spot and not spread out all over the place in each Data Source. The latter is a maintenance and support nightmare.
To begin adding a data service click

On the right hand side enter a name and optionally a description.

Set the Compute URL field based on the identified compute node above. Its form is “https://domain:port/dispatch”. A sample is shown below.
Also choose the “DynamoDB” driver.
Specify the DynamoDB endpoint in the server template field. The general endpoint format is
A sample endpoint which is used as the Qarbine server template value is
For possible endpoints see https://docs.aws.amazon.com/general/latest/gr/ddb.html

Specify your AWS credentials in the server options field.

Additional possible server options are:
- maxRetries,
- httpOptions.connectTimeout and
- httpOptions.timeout.
You can reference environment variables using the syntax %NAME%. The strings should be quoted and the key\value pairs separated by commas.
Test your settings by clicking on the toolbar image highlighted below.

The result should be

A misconfigured sample result is shown below.

Save the Data Service by clicking on the image highlighted below.

The data service will be known at the next log on time.
Sample IAM Access & Secret Creation
The access key ID and secret key ID values can be obtained using AWS IAM. There are several options of which one is described here.
Navigate to IAM.
Choose a user or create one.
Click

Under

chose

Click

Click

Enter a description

Click

The following is shown
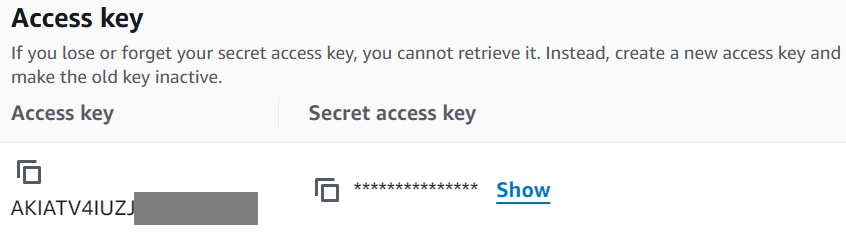
Copy the access key into a temporary area.

Copy the secret key into a temporary area.

Note- These values may be referenced within Qarbine’s data service definition using environment variables. It is up to you to set them on your deployed Qarbine VM following your security policies.
References
For more information see https://docs.aws.amazon.com/dynamodb/.
Example Data
Overview
The standard Qarbine installation includes many types of example components from queries to publication quality templates. Each Data Source references a Data Service which is defined by the Qarbine administrator which may not be defined “out of the box”. Some Qarbine examples such as those using MongoDB have access to publicly accessible sample data. That is not the case with the AWS DynamoDB examples.
An example of running a DynamoDB example component may show.

This likely indicates that there is no Qarbine Data Service yet defined literally named “AWS DynamoDB”. This would be the case for a fresh installation. Another possible querying error is shown below.
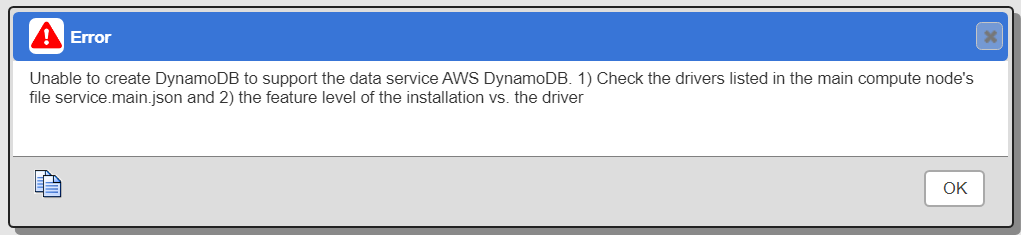
In this case on the Qarbine host, review the service.main.json file for the section listing the drivers to be loaded. The required entry is shown below.
"drivers" :[
"./driver/dynamoDbDriver.js",
Note that whenever a new Data Service is defined, have any affected users log out and then log back in to see the data service changes.
Loading Sample Data
For some data drivers there is a sample data file and optionally code to load that data. For sample DynamoDB data the Qarbine Administrator can SSH into the Qarbine host and review the contents of the ˜/qarbine.service/sample/aws/dynamodb folder. It contains:
| listTables.js | The node.js to test connectivity and list tables. |
|---|---|
| createMovies.js | The node.js to create the movie table. |
| loadMovies.js | The node.js to load the example data. |
| movies.json | The example data. |
SSH into the Qarbine host.
Navigate to the utility folder.
cd ~/qarbine.service/sample/dynamoDB
Using vi, edit the JavaScript files with your settings for the following.
AWS.config.update({
region: "us-east-1",
endpoint: "dynamodb.us-east-1.amazonaws.com",
accessKeyId : 'YOUR_KEY',
secretAccessKey : 'YOUR_SECRET',
});
The privileges needed to create and load the sample data is AmazonDynamoDBFullAccess while regular Qarbine Data Service privileges should be AmazonDynamoDBReadOnlyAccess.
Verify network connectivity and other permissions for the target DynamoDB installation. Sanity check access by running
node listTables.js
To create the movie table run
node createMovies.js
A portion of the sample output is shown below
Created table. Table description JSON: {
"TableDescription": {
"AttributeDefinitions": [
{
"AttributeName": "year",
"AttributeType": "N"
},
{
"AttributeName": "title",
"AttributeType": "S"
}
],
"TableName": "Movies",
"KeySchema": [
{
"AttributeName": "year",
"KeyType": "HASH"
},
{
"AttributeName": "title",
"KeyType": "RANGE"
}
],
…
To populate the movie table run
node loadMovies.js
There are 4,609 movies in the tutorial data. The output for each inserted movie will be the element number and its title.A sample snippet is shown below.
4580 Love Sick Love
4581 Kickboxer
4582 The Bates Haunting
4583 The Sentinel
Once the data has been loaded then consider removing the accessKeyId and secretAccessKey values from the file.
Configuration
The Qarbine example components for DynamoDB reference the Qarbine Data Service named “AWS DynamoDB”. This Data Service is not defined “out of the box”. The referenced data service’s general definition is shown below. The name and the driver must match that shown below.



Use the access and secret values for the read only DynamoDB IAM credentials. The example Qarbine catalog components should now have access to the desired sample data.