DataStax
Overview
Qarbine uses the vector enabled API rather than the legacy ones which have been deprecated per https://docs.datastax.com/en/astra-db-serverless/api-reference/legacy-overview.html
DataStax’s native query interface uses a programmatic interface to retrieve data. The general use case is to identify a collection with data of interest. Next a filter and/or a vector of values is used to indicate a point in n-space from which to locate similar data. It is recommended that the query set at most how many items to retrieve using the “limit:” field.
Qarbine provides 2 query options for DataStax:
- JSON query structure and
- SQL-like request.
The latter is an interface that resides above the JSON query structure API. It can be more convenient to specify criteria using SQL than the more complex JSON structure approach. Most of the DataStax features are still accessible when using the SQL syntax so there is no loss of DataStax features or complex middleware in play.
JSON Based Query Structure
One way to specify a DataStax query in Qarbine is to use a JSON-like structure which looks like the following.
{
collection: string,
$vector: [...],
$vectorize: string,
nearText: string,
useAssistant: string,
nearVector: [...],
filter: { },
returnProperties: [ ],
projection: { },
includeSimilarity: boolean,
includeSortVector: boolean,
skip: number,
limit: number,
sort: { },
maxTimeMS: number,
namespace: string
}
For vector searches either the nearText, nearVector, $vector, or $vectorize field must be defined. If a nearText value is set, then the named Qarbine AI Assistant is used to obtain the embedding. If the $vectorize value is set, then the DataStax integration defined for the collection is used to obtain the embedding.
Remember the number of values in the vector must correspond to the same number within the index’s underlying data. Preferably the exact same model used to persist embedding sis used to obtain an embedding for querying.
Primary Options
The primary specification options are described below.
| Field | Description |
|---|---|
| collection | The collection to perform the query upon. |
| $vector | The list of embeddings from which to determine similarity. |
| nearVector | The equivalent of $vector. |
| $vectorize | The phrase to obtain an embedding for to use in the query. Preferably this is actually set in the sort object. |
| nearText | The value is a string with the similarity phrase. For example, “dracula movies”. An embedding value for the nearText argument will be obtained by Qarbine using a configured Qarbine AI Assistant. When using this option, the model used to insert the data must correspond to the one used by the Qarbine AI Assistant. |
| useAssistant | For nearText, this indicates a specific AI Assistant to use to obtain the embedding. |
| returnProperties | The list of field names to return for each matching element. An example is [“color”]. By default any vector field is not returned in order to reduce the answer set size. If you want the vector values, then explicitly list it here or use the includeSortVector flag. To get all the fields and the vector field use something like the following, returnProperties: [ '*', 'vector'] |
| projection | The object indicating what fields to include or exclude See the discussion below for details. |
| includeSimilarity | A boolean indicating whether to include the similarity score in the results |
| includeSortVector | A boolean indicating whether to include the vector list in the results. |
| filter | The filtering object. See the section below for more information. |
| skip | It indicates how many objects of the answer set to skip over as part of the returned answer set. |
| limit | The maximum number of matches to return. |
| sort | The object indicating how to order the results. |
| maxTimeMs | The maximum time to run the query before timing out. |
Filtering Data
The filter argument is a JSON object representing the criteria. In brief, the filtering offers a subset of operators similar to MongoDB.
| Operator | Description |
|---|---|
| $eq | Equal to (number, string, boolean) |
| $ne | Not equal to (number, string, boolean) |
| $gt | Greater than (number) |
| $gte | Greater than or equal to (number) |
| $lt | Less than (number) |
| $lte | Less than or equal to (number) |
| $in | In array (string or number) |
| $nin | Not in array (string or number) |
These operators can be combined with $and and $or. The details on using operators are at
https://docs.datastax.com/en/astra-db-serverless/api-reference/documents.html#operators
There are several items to note on the following liinks
https://docs.datastax.com/en/astra-db-serverless/api-reference/document-methods/find.html
Some things to keep in mind are:
- Sort and filter operations can use only indexed fields.
Finding Distinct Values
Note that distinct is a client-side operation, which effectively browses all required documents using the logic of the find command, and then collects the unique values found for key. Below is a framework for the JSON specification.
{
collection: "movies",
distinct: field,
filter: { },
maxTimeMS: number,
limit: number,
sortValues: 'asc', ← asc, ascIns, desc, or descIns (“Ins” is for case insensitive)
}
A sample JSON specification is shown below.
{
collection:"movies",
distinct: 'criticname',
filter: { criticname: { $ne: 'Avi Offer' } },
sortValues: 'asc',
// This limit applies after all the above has been done.
limit: 10
}
An equivalent SQL syntax version is shown below
SELECT DISTINCT criticname
FROM movies
WHERE criticname <> 'Avi Offer'
order by criticname asc
limit 10
Managing What Data is Returned
The native DataStax field used to control this is “projection”. This key\value pair
is the same as the “returnProperties” field shorthand option of
You can mix the two with the returnProperties taking precedence of projection ones.
For complete details on DataStax projection option see https://docs.datastax.com/en/astra-db-serverless/api-reference/documents.html#projection-operations
For regular fields, a projection can’t mix include and exclude projections. It can contain only true or only false values for regular fields. The special fields _id, $vector, and $vectorize have individual default inclusion and exclusion rules. You can set the projection values for these independently of regular fields.
The _id field is included by default. The $vector and $vectorize fields are excluded by default. The $similarity key isn’t a document field, and you can’t use this key in a projection. The $similarity value is the result of a vector ANN search operation with $vector or $vectorize. Use the includeSimilarity parameter to control the presence of $similarity in the response.
Qarbine SQL Interface
Overview
DataStax supports semantic (i.e. vector) search and a lexical (i.e. scalar/matching) search. The use of the specification structure described above can be a bit verbose and cumbersome though. To improve readability and productivity when authoring DataStax retrievals, Qarbine provides a SQL oriented option. The Qarbine SQL interface below translates the SQL clauses into the equivalent native DataStax filter structure. Use the explain feature described below to confirm this. If things are not what you expect, then use the JSON structure interface.
SQL Oriented Filtering
Here is an example of a specification based search retrieval.
{
collection:"movies",
filter: { criticname: { $ne: 'Avi Offer' } },
limit: 10
}
The equivalent Qarbine SQL is simply
SELECT *
FROM movies
WHERE criticname <> 'Avi Offer'
limit 10
For many retrievals the SQL approach is a much more approachable way to specify the criteria. The mapping of the standard SQL clauses to their DataStax equivalents is described below.
| Clause | Description |
|---|---|
| SELECT | The names of the fields to return. Specifying “*” indicates all object fields . This does not set the returnProperties field in which case DataStax returns all of the properties. Here are some examples. SELECT * … SELECT _id, title, rating … SELECT _id, title, rating, similarity Note there is no leading $ in the “similarity” column reference to set includeSimilarity to true. Likewise, specifying “vector” rather than “$vector” sets the includeSortVector flag to true. |
| FROM | The name of the collection. This value sets the “collection” field in the query specification. |
| WHERE | The effect is to set the “filter” field of the query specification. |
| ORDER BY | The sorting rules in “column asc|desc” format. |
| OFFSET | Indicates where in the the return objects start return objects. This sets the “skip” field of the query specification. |
| LIMIT | Indicates at most how many elements to return. This sets the “limit” field of the query specification. |
Bear in mind that some combinations of query fields may not make sense in the DataStax world.
The WHERE clause criteria can be in a variety of traditional SQL forms and may include Qarbine specific functions described below. For example,
select * from Movies
where nearText("dracula")
results in a query specification with these fields,
collection: "Movies",
nearText: "dracula"
Some additional Qarbine defined SQL functions are listed below.
nearVector(number1, number n …)
nearText(aPhrase)
vectorize(aPhrase)
vector = (number 1, number n ...) ← A different way of expressing nearVector()
Note that a SQL list is enclosed in parentheses while one in the JSON specification is enclosed in brackets. That is a subtle nuance across the SQL and JSON syntax standards.
The table below describes their use and a few others.
| Function | Description |
|---|---|
| nearVector | This clause is removed from the WHERE criteria and its list of numbers argument set into the “nearVector” field of the query specification. |
| nearText | This clause is removed from the WHERE criteria and its argument set into the “nearText” field of the query specification. |
| vectorize | Pass in a string argument that ends up in the query specification as “$vectorize: theString”. |
| vector = (...) | Provide the embedding enclosed in parenthesis. This ends up in the query specification as “$vector: [...]”. |
| withOption | Pass in the specification field name and the value to set. This clause is removed from the WHERE clause. This is a way to set a query specification field that is not readily translated from the SQL world. |
| withOptions | Set several specification fields at once. The format is withOptions(key1, value1, keyN, valueN).The key argument may use dot notation when setting the inner value of a component object. |
There are several SQL functions which are used to easily access the DataStax filter features. They are listed below. For reference see the DataStax page at https://docs.datastax.com/en/astra-db-serverless/api-reference/documents.html#operators
| Function | Description |
|---|---|
| fieldExists(field) | This maps to the DataStax $exist clause. It matches documents that have the specified property. { "title" : {"$exists" : true} } An example use is shown below. where fieldExists('title') This can be combined with the NOT operator as shown below. where not fieldExists('title') This results in the DataStax clause { "title" : {"$exists" : false} } |
| size(field, howMany) | This maps to the DataStax $size clause. It selects documents where the array has the specified number of elements. { "someList" : {"$size" : 2 } } An example use is shown below. where size('someList', 2) |
| listIs(field, values) | This maps to the DataStax $all clause. It matches arrays that contain all elements in the specified array. { "food" : {"$all" : ['apple', 'orange'] } } An example use is shown below. where listIs(‘food’, ('apple', 'orange') ) An alternative is to use the following syntax. where food = ('apple', 'orange') DataStax may perform optimizations when $all is used so it is the recommended approach. |
Blending JSON and SQL
There are techniques to blend the ease of using SQL along with the powerful features of DataStax within a Qarbine JSON specification object. The table below lists the fields that drive this definition.
| JSON Field | Description |
|---|---|
| sql | The SQL statement can affect most all of the primary options listed above. |
| sqlWhere | The string can affect mainly the filter option above. |
Here is a simple example of combining the SQL and query specification approaches. The effective result is the same as the example query specification above.
{
collection:"movies",
sqlWhere: "criticname = 'Avi Offer'",
limit: 10
}
Vector Queries
Prerequisites
Prior to using Qarbine’s embeddings(...) macro function or the SQL-like query function nearText(...), the Qarbine Administrator must first configure “AI Assistant(s)”. The AI Assistants provide access to various popular Generative AI services and are referenced using an alias. Check with your Qarbine administrator for which ones are available and their proper use. For example, when using dynamic query vector embeddings, the model used by the AI Assistant must be compatible with the one used to generate the original embedding values in the database.
Searches
For details on DataStax vector searches see the information at
https://docs.datastax.com/en/astra-db-serverless/databases/vector-search.html
There are several ways to use vector values in a query:
- Explicitly embedding values.
- Use DataStax $vectorize for the associated DataStax AI integration to obtain the embeddings.
- Use Qarbine’s preprocessing to obtain the embeddings from a Qarbine AI Assistant configured by the Qarbine administrator.
The table below maps between the JSON structure and the SQL equivalent.
| JSON Structure | SQL Clause |
|---|---|
| sort: { $vector: [0.15, 0.1, 0.1, 0.35, 0.55] } | nearVector(0.15, 0.1, 0.1, 0.35, 0.55) |
| sort: { $vectorize: "foo" } | vectorize(“foo”) |
| sort: { $vector: [! embeddings("foo", "myOpenAi") !] } | nextText(“foo”) |
Reviewing the Generated Specification
You can enter criteria of the form “EXPLAIN SELECT ….” to have the SQL statement processed and have the returned answer set be the underlying query specification. For example enter and run
explain
select * from movies
where title <= 'Paa'
order by title limit 20
Select the single result element and its details are shown to the right.
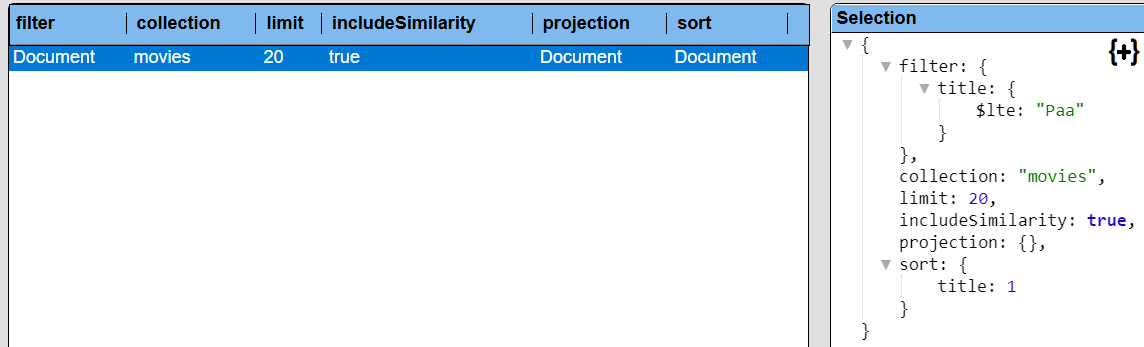
If necessary, click the “+” to expand all of the JSON object fields.
A convenient way of specifying this is to have “explain” on the first line and the rest of your SQL on the next lines.
explain
select * from movies
where title <= 'Paa'
order by title limit 20
Then simply “comment out” the first line when not in use
// explain
select * from movies
where title <= 'Paa'
order by title limit 20
You can also use “explain: true” in the JSON query specification for similar information.
Another way to get the specification is to press ALT and click  . Below is a sample result.
. Below is a sample result.
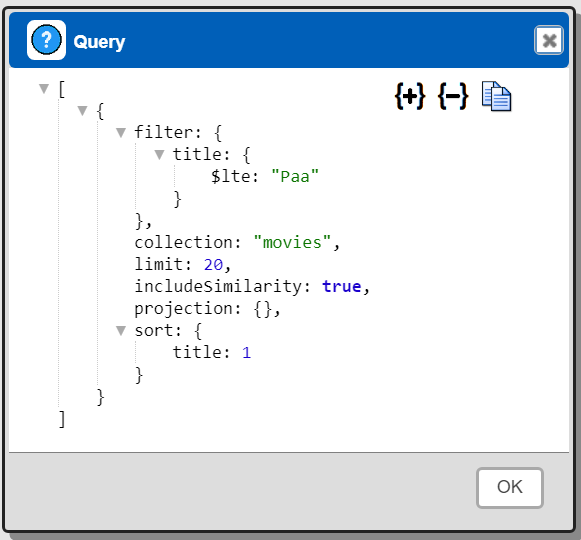
Any “explain SELECT” or “explain: true” takes precedence over the ALT-click interaction.
Qarbine Virtual Queries
There are a few convenience queries which are mainly DBA oriented. These queries are recognized by the Qarbine driver and provide common database information.
| Query | Description |
|---|---|
| list databases | Return a list of databases. |
| describe database | Return the details of the default database. |
| describe databases | Return the details of all the visible databases. |
| list collections | Return a list of collections. |
| describe collections | Provide details on all of the collections. This may take a while depending on your database structure. |
| describe collection COLLECTION | Provide details on the given collection. |
| list keyspaces | Return a list of keyspace names. |
| tally collections | Return the estimated document count for all collections. |
| tally collection COLLECTION | Return estimated document count for the given collection. |
See the “DBA Productivity” section of the online documentation for more details.
Troubleshooting
Node.js
Below is a sample node.js program framework to evaluate your queries.
var { DataAPIClient, VectorDoc, UUID } = require('@datastax/astra-db-ts');
const client = new DataAPIClient(YOUR_APPLICATION_TOKEN);
const db = client.db(YOUR_ENDPOINT);
(async function () {
const collection = await db.collection('vector_test');
const cursor = await collection.find(
{ },
{
sort: { $vector: [0.15, 0.1, 0.1, 0.35, 0.55] },
limit: 10,
includeSimilarity: true,
});
console.log('* Search results:');
for await (const doc of cursor) {
console.log(JSON.stringify(doc, null, 2) );
console.log();
}
})();
CQL Console
Some queries can be reviewed using the CQL Console. Sign on to Datastax and navigate to your database.
Open the CQL console by clicking

Type in, paste or otherwise edit the query.
Run the query.
Review the output and adjust as necessary.