Neptune
Querying Overview
Neptune provides 2 querying styles:
- Gremlin and
- openCypher.
Gremlin and openCypher are both property-graph query languages, and they are complementary in many ways. Gremlin was designed to appeal to programmers and fit seamlessly into code. As a result, Gremlin is imperative by design, whereas openCypher's declarative syntax may feel more familiar for people with SQL or SPARQL experience.
Queries in either language can operate on the same graph regardless of which of the two languages was used to enter that data. You may find it more convenient to use Gremlin for some things and openCypher for others, depending on what you're doing.
There are a few exceptions noted in the section below regarding Qarbine virtual queries.
Configuring an AWS Neptune data service with the Gremlin driver allows you to use both openCypher and Gremlin querying for that data service. This provides you flexibility to move between the two query languages and not have to define separate data services which are query language specific.
When using a Qarbine data service configured with the Gremlin driver to access AWS Neptune indicate Cypher querying by
- having the first token be “MATCH” or
- prefixing the query with “cypher ”.
The text being reviewed excludes comment lines, Gremlin pragma lines, and Qarbine pragma lines. This query
MATCH (p:Person)
RETURN p
and the following one both send the same text to Neptune.
cypher MATCH (p:Person)
RETURN p
Prerequisites
Prior to using Qarbine’s embeddings(...) macro function the Qarbine Administrator must first configure “AI Assistant(s)”. The AI Assistants provide access to various popular Generative AI services and are referenced using an alias. Check with your Qarbine administrator for which ones are available and their proper use. For example, when using dynamic query vector embeddings, the model used by the AI Assistant must be compatible with the one used to generate the original embedding values in the database.
openCypher Querying
A starting point for openCypher querying and Neptune is at
https://docs.aws.amazon.com/neptune/latest/userguide/access-graph-opencypher.html
In openCypher, you use a declarative syntax, inspired by SQL, that specifies a pattern of nodes and relationships to find in your graph using a motif syntax (like ()-[]->()). An openCypher query often starts with a MATCH clause, followed by other clauses such as WHERE, WITH, and RETURN.
Cypher provides a visual way of matching patterns and relationships by having its own design based on ASCII-art type of syntax:
(:nodes)-[:ARE_CONNECTED_TO]->(:otherNodes)
Round brackets are used to represent (:Nodes), and -[:ARROWS]→ to represent a relationship between the (:Nodes). With this query syntax, you can perform read operations on your graph.
Some of the material below is a subset from https://neo4j.com/docs/getting-started/cypher/
A graph database consists mainly of nodes and relationships. Nodes are often used to represent nouns or objects in your data model. In Cypher, you can depict a node by surrounding it with parentheses, e.g. (node). Relationships are represented as square brackets and an arrow connecting two nodes (e.g. (Node1)-[ ]→(Node2)). Relationships always have a direction which is indicated by an arrow.
They can go from left to right:
(p:Person)-[:LIKES]->(t:Technology)
From right to left:
(p:Person)<-[:LIKES]-(t:Technology)
Or be undirected (where the direction is not specified):
MATCH (p:Person)-[:LIKES]-(t:Technology)
Some Qarbine examples make use of Cypher variables which are different from Qarbine variables in this context. They are similar to SQL aliases in usage. Here is a query without a variable
MATCH (:Person)
RETURN Person
Here is one using a variable
MATCH (p:Person)
RETURN p
A Neo4j guide to their Cypher implementation with lots of discussion areas is at
https://neo4j.com/docs/cypher-manual/current/introduction/
Here is a guide on migrating from Neo4j to Neptune.
https://docs.aws.amazon.com/neptune/latest/userguide/migration-opencypher-rewrites.html
Gremlin Querying
A starting point for Gremlin querying is at
https://docs.aws.amazon.com/neptune/latest/userguide/access-graph-gremlin.html
Amazon Neptune is compatible with Apache TinkerPop3 and Gremlin. You can use the Gremlin traversal language to query Neptune. For differences in the Neptune implementation of Gremlin, see Gremlin standards compliance page found at
https://docs.aws.amazon.com/neptune/latest/userguide/access-graph-gremlin-differences.html.
Different Neptune engine versions support different Gremlin versions. Note that AWS Neptune provides both a Gremlin and a Neo4j compatible interactions on the same underlying data. See the separate Qarbine Neo4j tutorial for that style of interfacing.
Gremlin uses an imperative syntax that lets you control how you move through your graph in a series of steps, each of which takes in a stream of data, performs some action on it (using a filter, map, and so forth), and then outputs the results to the next step. A Gremlin query commonly takes the form, g.V(), followed by additional steps.
An excellent multi-series blog on Neptune querying can be found at https://aws.amazon.com/blogs/database/let-me-graph-that-for-you-part-1-air-routes/
Explaining Queries
Neptune provides an extension to obtain query plans from the Neptune engine. See the following page for more details on this Neptune feature
https://docs.aws.amazon.com/neptune/latest/userguide/gremlin-explain-api.html
The original query specification shown below
%%gremlin -p v,inv,inv
g.V().has('airport','code','LHR')
.out().out().has('code','SJC').limit(15)
.path().by('code').toList()
can be updated with the “explain” keyword as shown below.
%%gremlin -p v,inv,inv
explain g.V().has('airport','code','LHR')
.out().out().has('code','SJC').limit(15)
.path().by('code').toList()
Any “%%gremlin” line is removed from what is sent to Neptune. The “.toList()” is required for regular Qarbine interaction and is automatically removed prior to asking Neptune for the query plan details. Sample output within the Data Source Designer is shown below.

Qarbine has a default “explain” feature as well which returns the query just prior to running it. This is useful to see how variables and embedded macro functions within the original query specification are replaced. To access this feature start the query with “qexplain” to avoid confusion with the native Neptune explain functionality.
Reviewing the Generated Specification
You can press ALT and click  to have the statement processed and have the returned answer set be the underlying query specification. THe query is not actually run.
to have the statement processed and have the returned answer set be the underlying query specification. THe query is not actually run.
Qarbine Example Components
There are many examples of Neptune components in the catalog folder with the path shown below.



General Query Handling
Gremlin queries are preprocessed to remove ‘//’ comment lines and perform some syntax checking prior to being passed to the back end for evaluation. Many uses of Gremlin include Notebooks to retrieve and visualize graph data. Several of the common conventions used in those tools are supported such as visualization hints.
Gremlin Pragmas
The ‘%%gremlin’ prefix is commonly used with Notebooks and other tools which include a visualization feature. The most common argument is ‘-p’ or “-path-pattern” which provides display hints about the rows. Qarbine will notice this and create additional information as a part of the answer set. It is available when running a template via getMetaData*() macro functions. This extra information includes the items listed below.
| Keyword | Description |
|---|---|
| nodes | The list of unique nodes (vertices). |
| links | The list of links (edges). Links have ‘from’ and ‘to’ fields with values corresponding to a node. |
| pathHints | The original Gremlin argument. |
| pathHintActions | The derived pathway actions used by Qarbine. These are used to build the “pathString” property for each row. |
Qarbine Pragmas
Usage
Your queries may be defined using multiple lines of text for formatting and other purposes. There are a few recognized lines that are preprocessed by Qarbine and not sent to the backend data.
| Starts With | Description |
|---|---|
| // | Used to comment out a line as noted above. |
| #pragma | Several pragma keywords are recognized in general and a few for specific data drivers. |
Pragmas are directives to Qarbine to support your query interactions. See the details on using Qarbine pragmas in the Data Source Designer guide.
NOTE- Qarbine “#pragma…” line must appear above any “%%pragma…” line meant for Gremlin’s use.
Below are the additional pragmas recognized by the Qarbine Gremlin driver. The pragmas include directives on which objects are made directly available within the evaluation context rather than requiring dot notation. The 'g', 'process', and 'structure' values are always set. Referencing each of the following makes the properties of the item accessible without requiring a prefix.
- process
- t
- cardinality
- order
- statics
You may have none of the above pragmas at all or use 'defaultVariables'. The latter is needed if non-context directives are being used. The defaults are
t, cardinality, order, and statics (as '__').
Additional Qarbine pragma options from Gremlin are listed in the table below.
| Pragma Keyword | Description |
|---|---|
| removeRowLabels | Some queries will return rows with a ‘labels’ field that is really not wanted. Rather than include this in the answer set reply, use this pragma to remove them on the server-side. This reduces the size of the network payload. You can also provide a CSV list of immediate child fields to adjust as well. |
| morphObjects | Some queries result in rows having an ‘objects’ field which is a list of values. Use this to create a row using specific CSV field names with those values. For example,#pragma morphObjects from, distance, to |
| morphMapIntoKeyValueList | Some queries return data which is a single row with multiple fields and their value. This creates a list of rows with the fields ‘key’ and ‘value’. |
| skipNodesAndLinksCreation | Use this to suppress the automatic creation of the metadata from pathHints mentioned in the %%gremlin section above. Qarbine looks at the Gremlin path hints provided to the --path-pattern argument. |
| defaultVariables | Include the Gremlin t, cardinality, order, and statics variables for use when evaluating Gremlin queries. Use this with the standard %%gremlin interactions. |
| removeLeadingTildas | When using openCypher with Neptune and the Gremlin driver objects with fields such as "˜id": "3644" and "˜entityType": "node" were observed. Use this pragma to remove the tildas (‘˜’) from the first level field names. Leading tildas not preferred for field names in Qarbine template formulas.You can also provide a CSV list of immediate child fields to adjust as well. |
Remember, there are several generally recognized pragmas as described in the Data Source Designer document here.
Sample removeLeadingTildas Interaction
This pragma adjusts first level field names with leading tildas (‘˜’) to their non-leading tilda names. This table below illustrates the impact of using this pragma.
| Without removeLeadingTildas | With removeLeadingTildas |
|---|---|
| #pragma pullFieldsUp airport cypher MATCH (airport) RETURN airport LIMIT 10 | #pragma pullFieldsUp airport #pragma removeLeadingTildas #pragma removeRowLabels cypher MATCH (airport) RETURN airport LIMIT 10 |
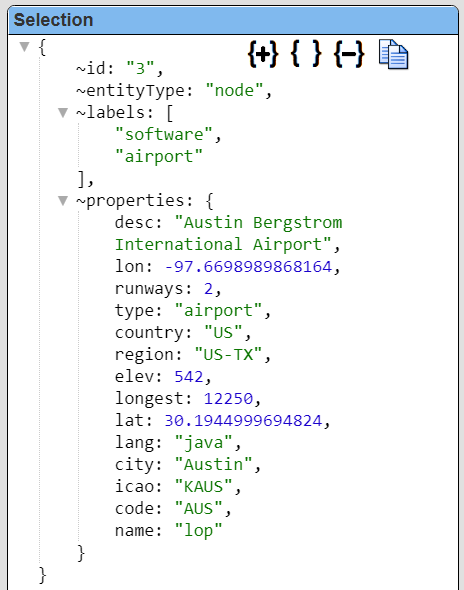 | 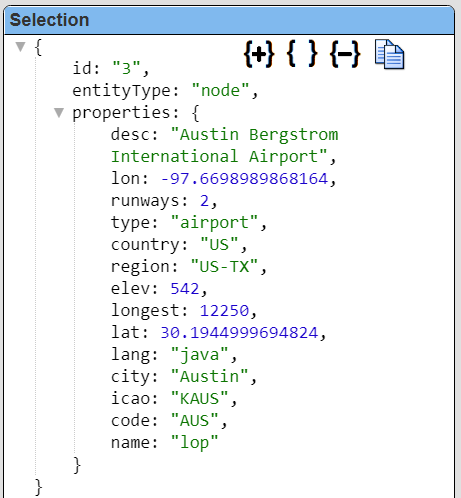 The pragmas generally run in order so removeRowLabels is after the tilda removal. A deleteFields pragma could have been done as well with the appropriate name. |
Sample morphObjects Interaction
This pragma will convert that single row into a row per field. Consider this query for determining routes longer than 840 miles.
g.V().hasLabel('airport').as('a')
.outE('route').has('dist',process.P.gt(8400))
.order().by('dist',process.order.desc)
.inV()
.where(process.P.lt('a')).by('code')
.path().by('code').by('dist').by('code')
.toList()
The basic answer set looks like

One of the rows looks like

Adding the following lines to the query,
#pragma morphObjects from, distance, to
results in the following output.

If you want to further filter or sort this list use the ‘postRunQuery’ pragma. For example,
#pragma postRunQuery select * from data where from= ‘SYD’
This results in a final list such as the one shown below. For efficiency of course, as much filtering as possible should be done within the native query.

Sample morphMapIntoKeyValueList Interaction
This pragma will convert that single row into a row per field. Consider this query
g.V().hasLabel('continent')
.group().by('desc').by(__.out('contains').count())
.order(process.scope.local).by(process.column.keys)
Sample output is shown below.

However, one challenge with this data is that you may not know the field names. Adding the following line to the query,
#pragma morphMapIntoKeyValueList
#pragma runPostQuery select * from data sort by 1
results in the following output.

You now have a list that can be easily iterated through and you know each element has ‘key’ and ‘value’ fields. Secondarily you may then want to filter and even sort this new result list.
Generating a Query Template
The Data Source Designer has a convenient pop up menu option shown below
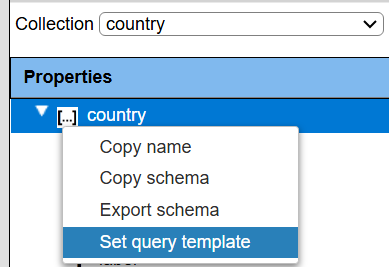
The template uses openCypher syntax. When chosen it generates a query similar to the one below.
#pragma pullFieldsUp country
#pragma removeLeadingTildas
MATCH (country)
RETURN country
LIMIT 25
This uses the pragmas above as a very convenient way to shape the answer set into a more usable form.
Qarbine Virtual Queries
As noted above, the primary query specification syntax is Cypher. There are a few exceptions to interacting with the database which are mainly DBA oriented. These queries are recognized by the Qarbine Gremlin driver and perform common database retrievals.
| Query | Description |
|---|---|
| list databases | Return a list of databases. |
| list labels | Return a list of Neptune labels. |
| describe labels | Provide details on all of the labels. This may take a while depending on your database structure. |
| describe label LABEL | Provide details on the given label. |
See the “DBA Productivity” section of the online documentation for more details.
Trouble Shooting
If this error dialog is shown when interacting with any of the tools or running queries
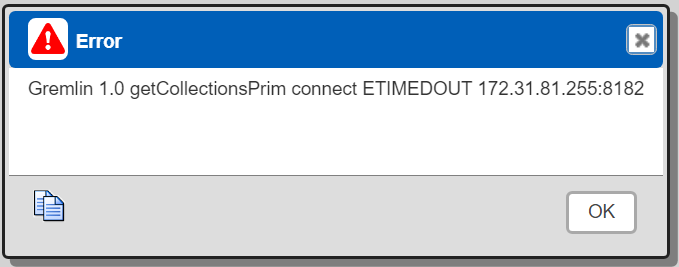
then check your AWS security group for access rules. Also verify the Neptune cluster is operational as this or similar console address page
https://us-east-1.console.aws.amazon.com/neptune/home?region=us-east-1#databases.:
IMPORTANT- The timeout can also occur because Neptune data access is ONLY available from within EC2! The settings test above will show basic access. But this is different from running Gremlin and openCypher queries.
Neptune Graph Explorer
You can visualize Gremlin graph query results in the Neptune workbench. For details see
https://docs.aws.amazon.com/neptune/latest/userguide/notebooks-visualization.html
Here are the labels in a sample Neptune data set.
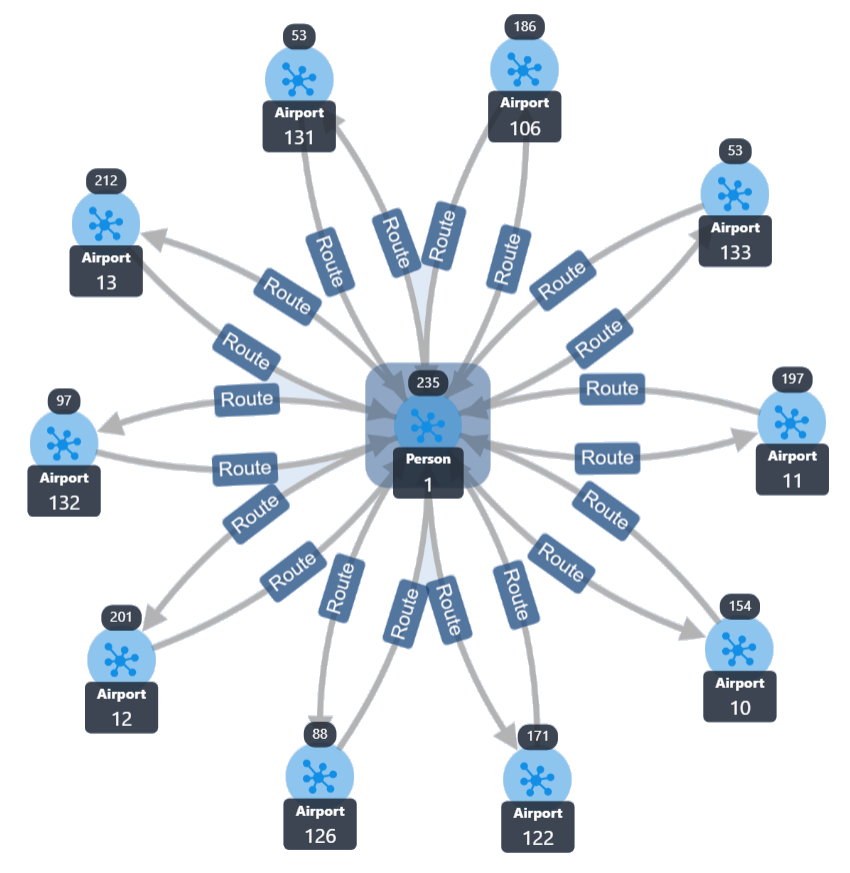
Below is the Person object with ID 1 viewed in the Graph Explorer.
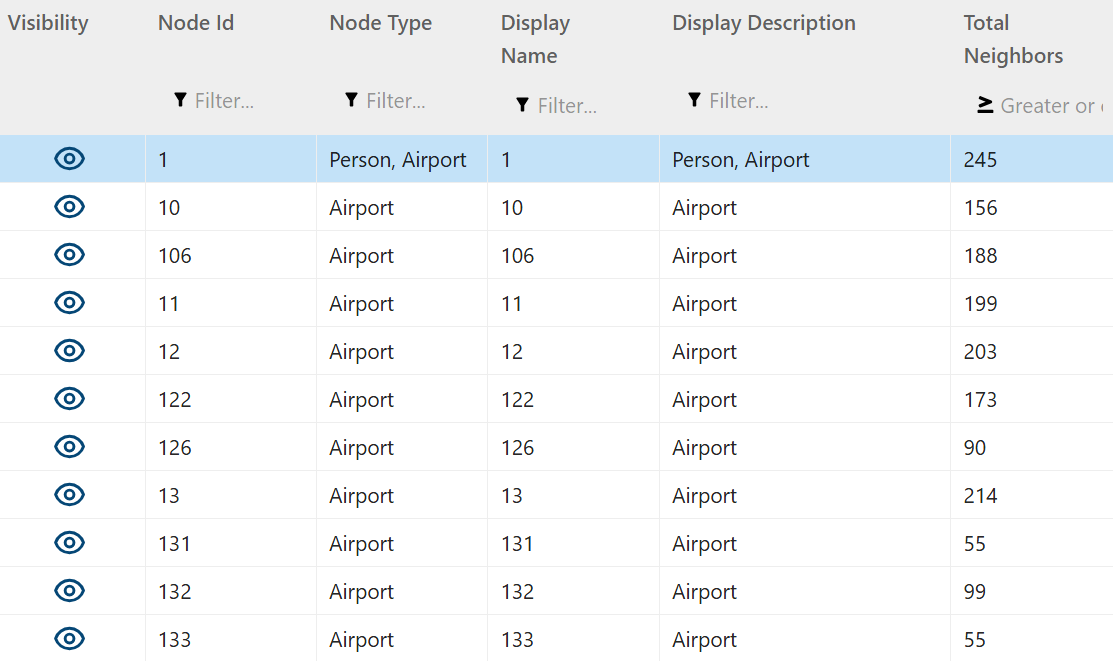
Here are the associated nodes.
A sample URL is
https://us-east-1.console.aws.amazon.com/neptune/home?region=us-east-1#notebook-details:id=aws-neptune-anotherNotebook