Ad hoc Querying
Overview
The Data Source Designer is used to run free form interactive queries. Unlike other popular querying tools, you can then save these queries as named objects complete with descriptions and access controls. They can then be easily discovered by others and even referenced by analytic templates to provide their data.
Walkthrough
Opening the Data Source Designer
This tool can be accessed in several ways including:
- from the sign on page

- from another tool’s upper left menu.

Indicating the Data Context
Top top-left area of the initial Data Source Designer is depicted below.
Briefly, a “Data service” is set up by the Qarbine Administrator to provide access to your data such as a MongoDB Atlas, DynamoDB, Couchbase, Milvus or other supported database instance. It indicates the Qarbine compute node to run the query and the target data endpoint to perform the query. A database service like MongoDB Atlas may further segregate information into separate databases. Databases then contain the actual data. In MongoDB they are called “collections” while in DynamoDB and traditional SQL data servers they are called “tables”.
NOTE- In most cases the Qarbine web pages use the label “Collections” to mean either collections or tables.
NOTE- If your database service is not MongoDB then refer to the database specific documentation guides within the Tutorial and Data Source Designer sections of Qarbine’s documentation.
Choose the “Sample Data Service” from the data service drop down.

Choose the “sample_mflix” from the database drop down.

This provides context on the database execution context for the query.
On the left hand side you can get a list of the database’s collections and the general structure of each as well. Make the selection as shown below.

The general properties will be shown with field names and data type information. The  icon indicates tree nodes can be expanded and contracted in the standard tree widget fashion.
icon indicates tree nodes can be expanded and contracted in the standard tree widget fashion.
| Top portion of the schema | Bottom portion of the schema |
|---|---|
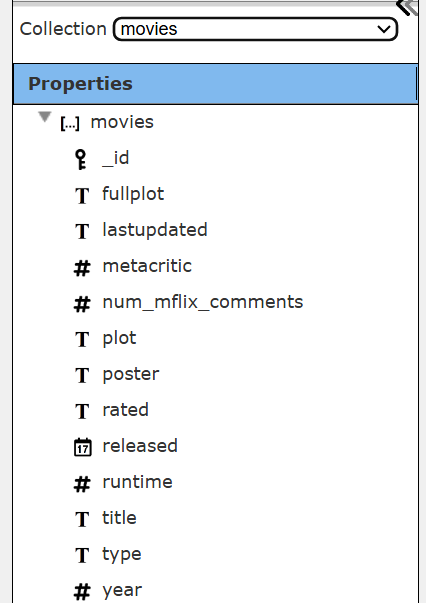 |  |
Entering your Query
In the text area enter the following query which retrieves the top 25 movies in 2014 based on award wins,
db.movies.find( { year: 2014}, {_id:0, rated: 1, title:1, runtime: 1, awards: 1, cast: 1} )
.sort( { "awards.wins" :-1} ).limit(25)
Click

The query is run.
Reviewing the Results
Sample results are shown below.

Note that the awards are an embedded document and the cast is an embedded array. Selecting one of the result elements shows its details to the list’s right.
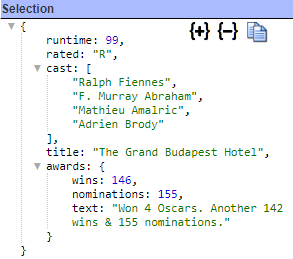
During early query development it may be preferred to limit the size of the answer ets. There are 2 primary ways to limit results.
- The preferred way is in the query itself. In this example we used the MongoDB limit function.
- The second way is to have the Qarbine compute node either set a data server request parameter or to truncate what it receives from the data server. The number of rows is set by clicking on the gear icon and feedback on the setting is shown to its right. A zero indicates no truncation.

Saving your Work
Click  to save the Data Source.
to save the Data Source.
Navigate to your private folder and select it.
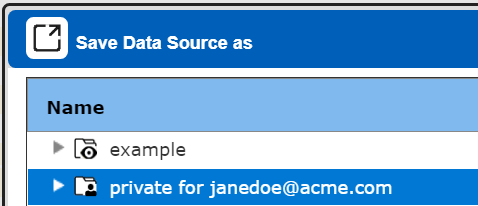
Enter a name as shown below

Your components can include longer descriptions and tags as well to better convey their purpose and group them in an ad hoc manner independent of their catalog folder location. Users can search the catalog by keywords and tags.
Depending on your Qarbine license and configuration, storage zones can be used to save components and analysis results in appropriate regions to adhere to GDPR or other regulations. The analysis results are more likely to contain data covered under regulations than the templates which are merely referencing field names.
Click

In a corporate Qarbine deployment, catalog folders can be set up for team members to share components. This enables those skilled in various querying languages to define data source components that others can simply locate and immediately use. The analysts do not have to be query experts to get the data they want to perform their responsibilities.
Next Steps
There are many other features of the Data Source Designer discussed in its own document.
For now, return to the “1) Qarbine Sandbox Bucket List” document which can be found alongside this document to continue the quick tour.