Deployment Considerations
Deployment Instructions
Review the following information prior to deployment to better understand configuration and other related areas. See the Getting Started;Deployment Wizard document for detailed instructions using the Deployment Wizard. The availability of some Qarbine features is based on the edition, release and other factors.
Resource Selection
The Qarbine node properties can vary to better support the databases they are interacting with. For example, the Qarbine administrator can configure an analysis to run on a specific node which is near the source data and deployed with optimal compute, storage, and network I/O. For AWS you can likely start with a basic t2.micro instance and then adjust based on your use cases.
Topology and Port Considerations
Deployment Overview
Qarbine is deployed as a VM by the customer within the customer’s VPC. An initial Qarbine deployment has a primary Qarbine node which provides the web application support and core service interactions. This node has an internal database containing your Qarbine configuration information and the catalog components used to retrieve data, analyze it, and present it. You can configure Qarbine to access multiple data endpoints which can span technologies, cloud providers, and geo-locations. Do not use the AWS or Azure account’s root user for any deployments or operations. Following the principle of least privilege for all access granted as part of your Qarbine deployment and also for the databases and endpoints it is interaction with.
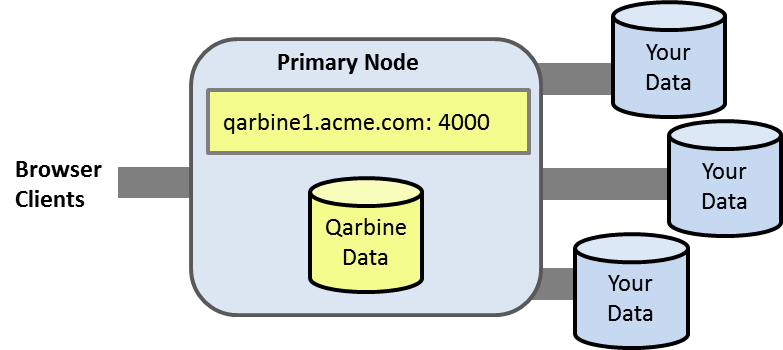
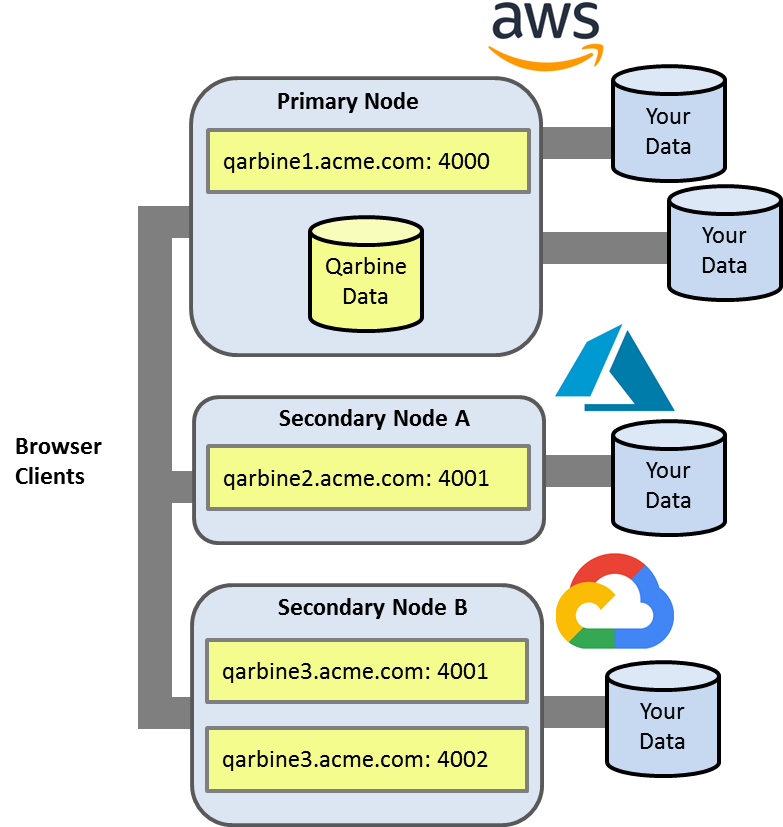
Some editions of Qarbine can optionally deploy secondary hosts as well for compute, data processing and other considerations. In addition, you may run multiple endpoints on a host as well. A sample topology is shown below with data of interest residing across AWS, Azure, and Google public clouds.
Background on Service Endpoints
The startServices.sh command file scans the ./config subfolder looking for service.* files. These represent the endpoints to start on the host. Each endpoint is bound to a different port. The availability of some Qarbine features is based on the edition, release and other factors.
The primary host compute node may be configured with the following mappings:
| Port | Name | Usage |
|---|---|---|
| 4000 | Main | System access, catalog, and other services |
| 4001 | Support1 | Runtime support for queries and reports |
| 4002 | Support2 | Runtime support for queries and reports |
Secondary host(s) may be configured with the following mappings:
| Port | Name | Usage |
|---|---|---|
| 4001 | Support3 | Runtime support for queries and reports |
The port numbers above are arbitrary but network access permissions and such need to be configured appropriately within the cloud or other operating environment you are running within.
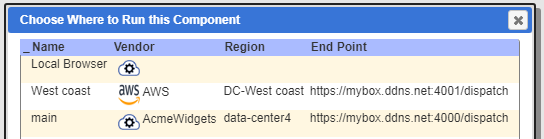
In these deployments the user may choose to run a particular query or analysis using a specific endpoint. This is accessed via the icon highlighted below.

A sample prompt dialog is shown below.
Each Qarbine compute node has a ‘config’ folder which indicates what functionality to run. The startServices.sh command picks up the “service.*” files and starts the associated endpoint.
General Port Usage
Common inbound ports to review for network accessibility are listed below. The available functionality varies by Qarbine feature and license edition levels.
| Port | Accessor | Comment |
|---|---|---|
| 80 | Clients | Access to primary node’s Qarbine installation. After installation this port redirects to port 443. |
| 443 | Clients | Access to the primary node’s Qarbine web application. |
| 4000 | Clients | For the primary node, enable access for others to its services. The port is configured in ./config/service.main.json. |
| 4001 | Clients | A sample compute service endpoint. Both user web browsers and other compute nodes must be considered for access. An end user may request a report be executed on any compute node and that compute node may require access to some other compute node referenced by the data service. This is configured in ./config/service.NAME.json. |
| 4010 | Slack corporate | Sample Slack endpoint. Configured in the Administration tool’s Settings tab. |
| 4011 | Zoom corporate | Sample Zoom endpoint. Configured in the Administration tool’s Settings tab. |
| 4012 | Azure corporate | Sample Microsoft Teams bot endpoint. Configured in the Administration tool’s Settings tab. |
| 37000 | Compute nodes | The default primary node’s internal MongoDB database port on the primary host. Open this as needed for access to the database. For example, using the MongoDB shell from an IT desktop. The port must also be accessible when cloning an installation from a target installation host.NOTE- When configured, cloud monitoring agents such as Datadog running on the main host require access to Qarbine’s internal MongoDB server for performance metrics via a read only account. Configuring such monitoring is described in their respective documents. |
Note- Some HTML images are fetched using a full URL with the DNS name of the host. This occurs when reports contain images. The “allow list” for port 443 MUST include the host’s own public IP address. Usually the URL is adjusted with the internal IP access so this is less necessary. When running reports on a remote compute node though, access must be granted to the primary host’s port 443 to obtain the images.
If reports are running on another compute node then those too must have permissions for ports 443, 4000, and others. Catalog interactions with the primary host are usually on port 4000 and other compute node operations on ports such as 4001. One secondary compute endpoint may require access to another compute node’s endpoint ports as well. Computer node configurations, like database deployments, can vary widely.
Browser Permissions
Browsers may be configured to ask end users for certain permissions. For example, to copy and paste Qarbine requires access to the clipboard. End users must answer “Allow”, or its equivalent, to the prompts shown below.

Potential Sensitive Information Locations
As a reporting and analysis application there are a few potential areas which may obtain sensitive information to be aware of. Certainly your application databases likely contain sensitive information and Qarbine Data Sources may retrieve that data during analysis and presentation. Users could then print, export, and save those results in various manners.
Qarbine components are stored in the Qarbine catalog within Qarbine’s internal database. This is usually running on the primary host. Qarbine users with sufficient privileges may author or view these components. It would generally be unlikely to include sensitive information in the following components.
| Area | Potential Sensitive Information Areas |
|---|---|
| In General | Component names and descriptions. |
| Data Sources | Query definitions with hardcoded values. |
| Templates | Labels and formulas. |
| Prompts | Labels and any formulas. |
| QBE, RBE and Report Wizard | Criteria and labels. |
| Prompts | Labels and formulas. |
| Data Services | The various properties likely contain endpoint and potential account information necessary to interact with the data. This information is only visible within the Qarbine Administrator tool. The accounts used by Qarbine to access data should always be read only. |
These components are more likely to end up containing sensitive information.
| Area | Potential Sensitive Information Areas |
|---|---|
| Report results | The output formatted from templates is based on the retrieved data and may have sensitive information. The report results are stored in ‘folders’ within the Qarbine catalog on the primary Qarbine node. The folders are either private to the user or potentially shared in some manner. The Qarbine administrator defines access to those shared folders and users can define individual access at the component level. |
| Data Set | These can be created from data source, QBE, RBE, and Report Wizard results. |
| Log records | These are Qarbine log records stored in the Qarbine internal database. |
| Log files | Similar to above but these are disk log files in /home/qarbine/pm2/logs or perhaps in the Apache log files in the /var/log/httpd folder which have run component parameters and general component interactions. Other files may be impacted depending on the instance configuration. The Apache logs are only on the primary compute node. All Qarbine compute nodes would have the pm2 log files. |
Security Policy Guidance
Encryption
Browser interactions with Qarbine are done over HTTPS. The certificates are configured during the Qarbine deployment process. JSON web tokens (JWT) are used to encrypt HTTPS content header authorization values. The keys are dynamically set during the deployment process and are maintained by the primary Qarbine host.
Public key cryptography is used for SSH access to the Qarbine compute node instances. Basic SSH password authentication is not used. The customer has OS-level administration capabilities for compliance requirements. vulnerability updates, and log access such as mentioned above.
Interactions between Qarbine hosts such as the primary and secondary nodes are done over SSL. This is for both internal endpoint and internal database interactions. The interactions from Qarbine to your data varies based on how you configure your Qarbine Data Services. Most databases for example provide SSL interactions of some sort. Refer to the Qarbine Data Service configuration documentation and especially that of your data endpoint for more details. This configuration is your responsibility.
Passwords
Qarbine user passwords are one way encrypted into hash values. The original password can not be determined from those hashes. This is also true for the Qarbine API keys used to obtain tokens for programmatic access. During Qarbine primary host deployment the Qarbine administrator account’s password is dynamically set and then must be changed at initial application sign on time. For AWS instances it is the dynamic instance identifier from the instance metadata. Application passwords must be between 6 to 20 characters and contain at least one numeric digit, one uppercase, and one lowercase letter.
Application Accounts
Qarbine application accounts can be deactivated, have expiration dates, and be limited to certain IP addresses. They can be part of a Qarbine Access Group as well which provides optional controls in an aggregated manner.
Network Access
The customer is responsible for appropriately configuring network access. The opening of ports is done during the instantiation of the VM within the hyperscale cloud vendor’s standard workflow. As a web application using a browser front end, HTTPS port 443 must be open to the primary Qarbine host. Also, HTTP port 80 is redirected to port 443 once a deployment has taken place. Port 4000 is the standard Qarbine service endpoint port. This can be changed at deployment time within the Deployment Wizard. Various network topologies are possible including those with VPNs and other special routing strategies. If multiple Qarbine endpoints are configured on a single host, then multiple ports must be opened up accordingly.
Use best practices when configuring your network access policies. This includes only exposing the minimally necessary host ports, especially your data endpoints. A browser based user needs access to a Qarbine compute node, but only Qarbine compute nodes need access to the underlying data endpoint to retrieve data. The browsing end user need not and should not have that privilege.
External Data Access
The Qarbine Administrator should define Data Services and assign their use in a need to access the data manner. Within the Qarbine Administrator tool Qarbine accounts (Principals) can be part of a Qarbine Access Group and each can be configured to only have access to specific data services. One database (i.e., a MongoDB endpoint) can be referenced by multiple data services but use different accounts which have different privileges. Client side end users just see the data service name in the browser- no details about the actual configuration is exposed to the browser world. The Qarbine administrator associates each data service with the Qarbine accounts and access groups as appropriate. They may also easily be limited or simply disabled.
Catalog and Component Access
Each Qarbine user has a private folder for storing components only visible to their account. The Qarbine Administrator can control access to the other component folders. Furthermore, component authors can adjust the type of interaction that other accounts are permitted for the non-private folders.
Internal Database TLS/SSL Enabling
The internal Qarbine database resides on the primary node and uses password authentication and authorization. When that is the only node operating in an installation, no further action is generally necessary as interactions are local and the port is not open. When secondary compute nodes are being used then TLS/SSL may be desired for inter-compute node interactions for secondary nodes to access the Qarbine catalog and to write log records.
The ./config/mongodb-tls.json file contains JSON configuration information for this purpose. Its general structure is shown below.
{
tls: true,
tlsCAFile: ”<path to CA certificate>”
tlsCertificateFile: ”<path to public client certificate>”,
tlsCertificateKeyFile: ”<path to private client key>”,
tlsAllowInvalidHostnames: false,
tlsAllowInvalidCertificates: false
}
| Item | Description |
|---|---|
| Certificate Authority (CA) | The certificate authority to trust when making a TLS connection. |
| Client Certificate | A digital certificate and key that allow the server to verify the identity of your application to establish an encrypted network connection. |
| Certificate Key | The client certificate private key file. This key is often included within the certificate file itself. |
A full description of TLS/SSL, PKI (Public Key Infrastructure) certificates, and Certificate Authority is beyond the scope of this document. This type of configuration assumes prior knowledge of TLS/SSL as well as access to valid certificate and key files. The generation of the Certificate Authority (CA), host certificate, and host key file are beyond the scope of this document. Verify that the qarbine account has permissions for the given locations of the files. When enabling this option, coordination must be done across the primary and secondary compute nodes.